MotionMactching基础
MotionMactching基础
 |
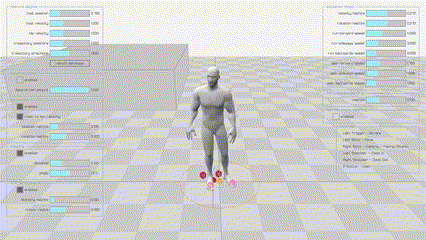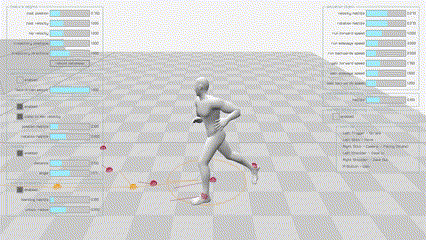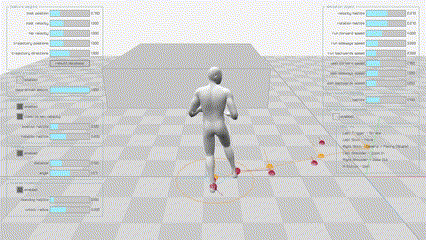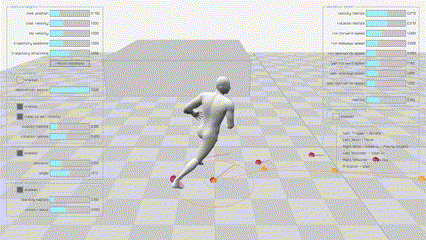 |
 |
|---|
Motion Matching简介
Motion Matching是由育碧在GDC2016上提出的一项技术,可以使角色动作更加流畅和真实。与其他方法相比,它不需要在动作图中构造动画片段的结构,不需要仔细地切分或同步它们,也不需要在状态之间显式地创建新的转换。现如今已经被广泛应用在3A游戏中,如《荣耀战魂》,《刺客信条:奥德赛》以及最近的《黑神话:悟空》团队也表明他们也会使用Motion Matching技术。
为什么要用Motion Matching
如果把游戏的动画系统想象成一个黑盒,我们希望用户输入指令,动画系统这个黑盒输出相应的动画。
动画状态机就是目前动画系统这个黑盒最常用的实现方式。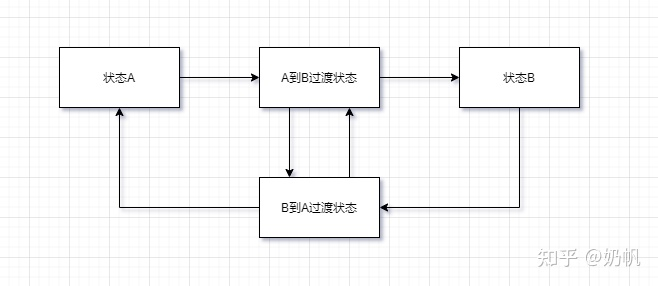
动画状态机需要设置不同的状态(例如走路,跑步),这些不同的状态分别对应不同的动画片段(Animation Clip),除了这些状态外还需要设置状态之间的切换条件,当满足这个条件时进行状态的切换也就是切换播放的动画片段。
动画状态机虽然很直观,但是其也有很多问题:
- 复杂度高:动画状态机需要设计和编写,对于复杂的游戏角色,需要设计更多的状态和转换,使得状态机的复杂度变得很高,需要耗费更多的时间和精力。
- 难以处理动画过渡:动画状态机中的动画过渡需要手动设置,需要设计人员具有一定的动画技能和经验,否则可能会导致角色动画的不自然和不流畅。
**Is there a way to deal with loops and transitions in a uniform way?**——Simon Clavet - “Motion Matching and The Road to Next-Gen Animation” - 难以适应变化:如果游戏需要进行修改或扩展,动画状态机可能需要进行重构或重写,这需要耗费更多的时间和精力。
- 有一些动作难以写入状态机

为了解决这些问题,育碧提出了Motion Matching。
Motion Matching的发展史
Motion Graphs
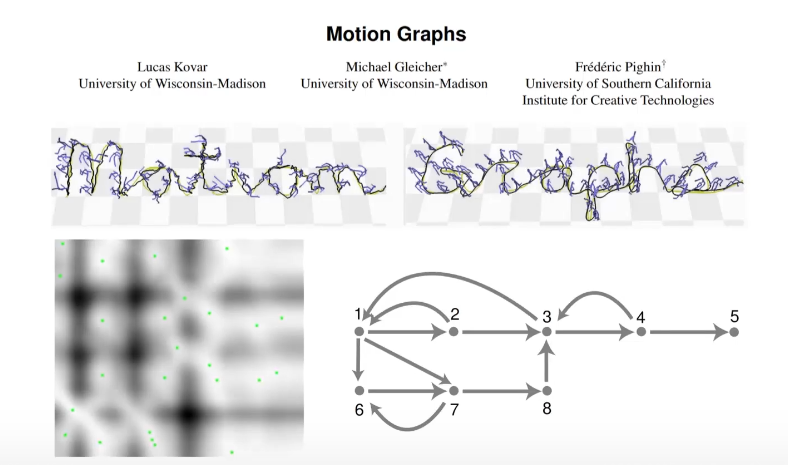
Motion Graphs是2002年的工作,他主要是对动画片段中的每一帧进行对比,得到最相似的两帧(可以是速度,位置,pose等等),就设置这两帧为可过渡点。
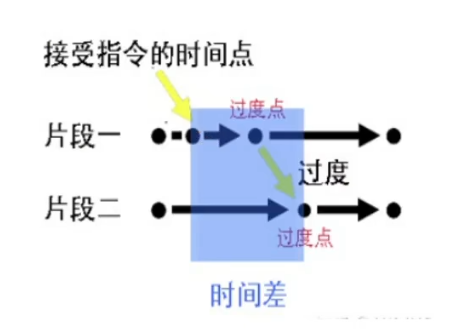
但是这篇工作中的过渡点是预先设定好的,导致动作反馈的及时性比较差,但是找到相似的动画作为下一帧动画的这个思想留给了后人。
Motion Fields
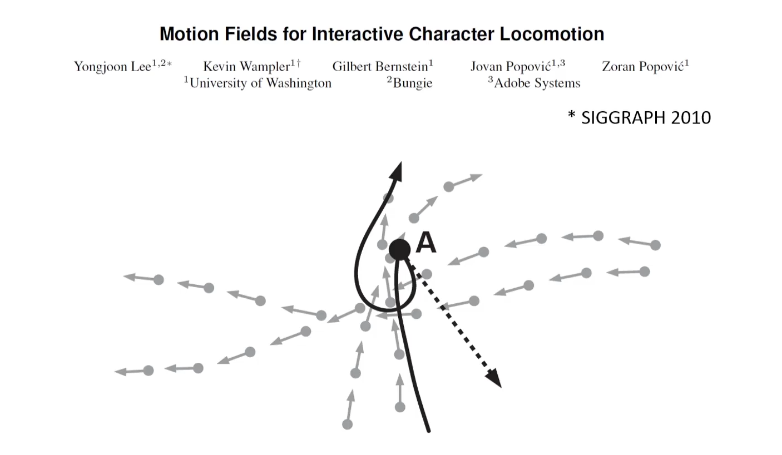
这个技术也是一个划时代的技术,其实现效果已经很接近motion matching了,但是其实现方式过于复杂。
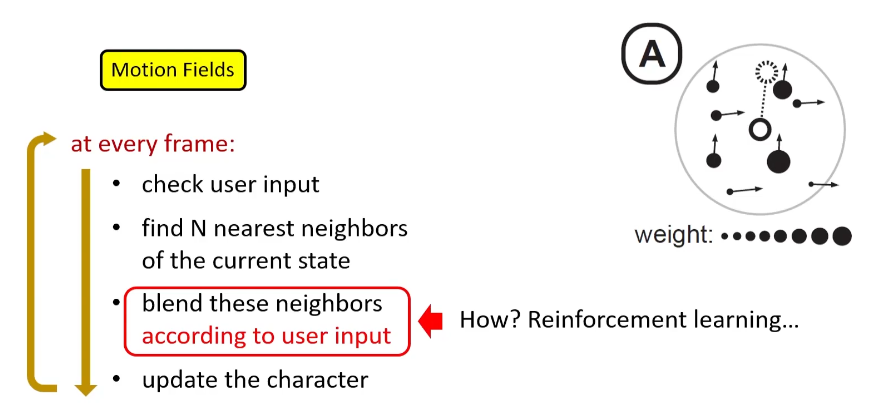
具体就不讲了,可以参考games105-lecture06,这篇工作虽然实现方式很复杂,但是其提供了一个重要的思想:我们可以转换到任何一个我们想要的动画帧。
motion matching就是在motion fields的基础上进行简化得来的。
Motion Matching的实现
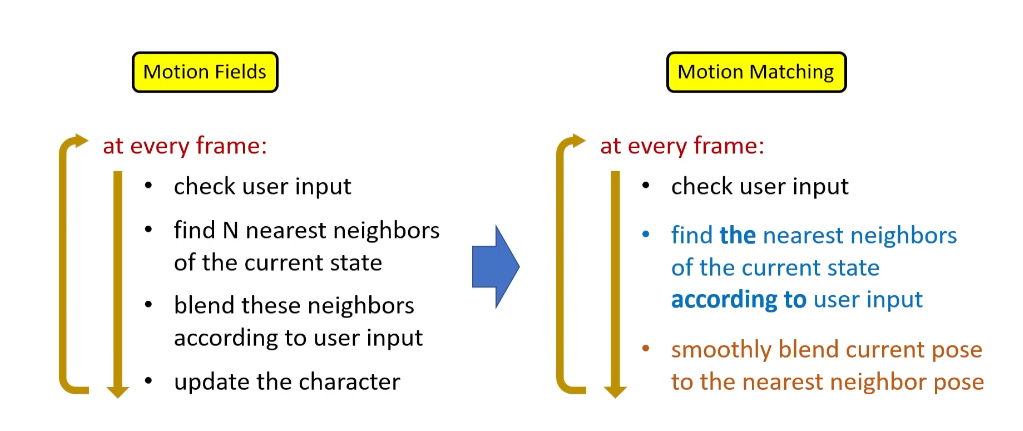
可以看出Motion Matching中最重要的就是如何找到动画数据库中满足用户输入的条件下与当前帧最相近的动画数据。 用其创始人Simon的话说,这是一个十分暴力的动画搜索方法。

动画数据库(实现Motion Matching的第一步)
 |
 |
 |
|---|
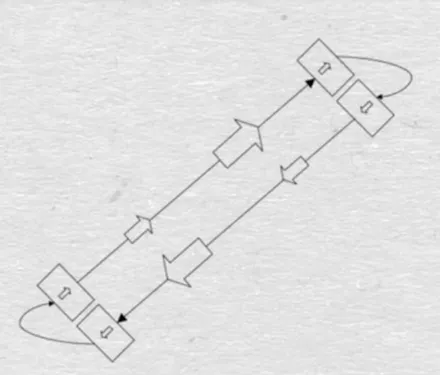
Motion Matching使用的动画数据大多来自动作捕捉,为了尽量高效的得到足够多的动作数据,育碧研究人员提出了一个概念叫Dance Card,动捕演员只需要按照Dance Card上的路径进行完成指定动作即可。
代码实现
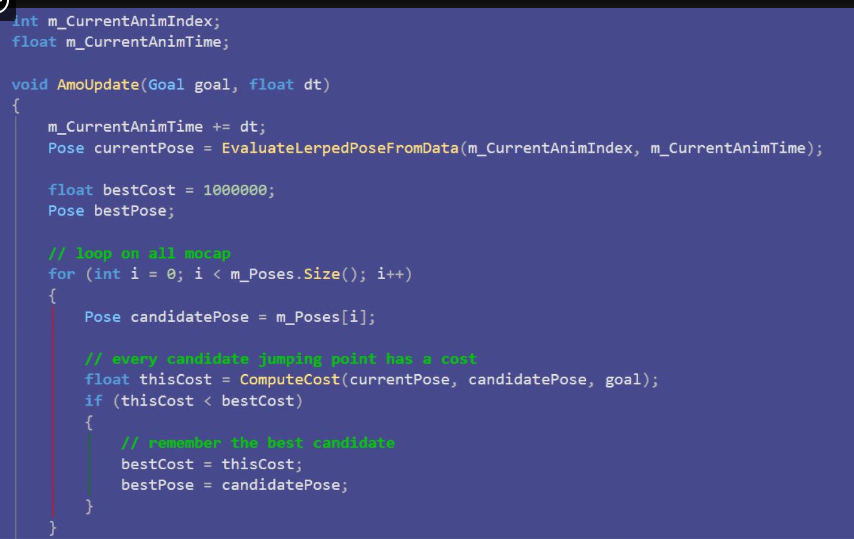
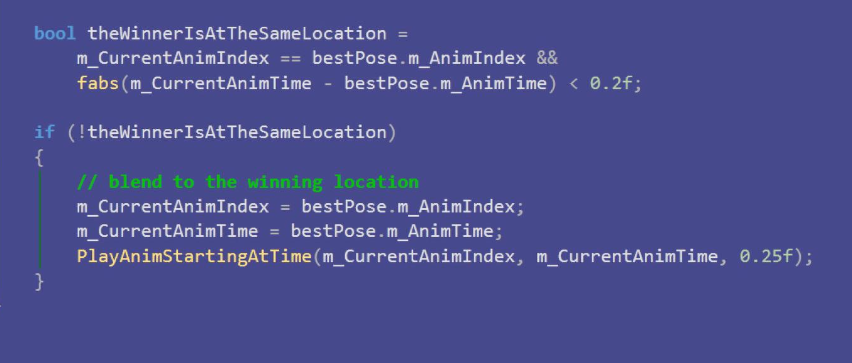

这就是育碧在GDC上给出的代码实现,也是Motion Matching的思路,十分简洁明了。可以看出关键点就是我们上文提出的如何选择下一个要过渡的动画帧,即ComputeCost这个函数。
源码把Cost分为了两部分(situation和trajectory),我们把计算Cost更直观的分为三部分:
- 姿态的Cost,表示候选动画帧姿态和当前姿态的匹配程度;
- 速度的Cost,表示候选动画帧的速度,加速度,角速度等信息与当前动画帧的匹配程度;
- 轨迹的Cost,表示候选动画帧轨迹和当前用户输入轨迹的匹配程度;
当然各个Cost要加权平均得到最终的Cost!
姿态Cost
角色动画数据本质就是定义了每个关节的旋转和位置,以及一些运动速度等信息。
在姿势匹配阶段,我们不需要匹配每一个关节的旋转和位置,只需要选取几个重要的关节即可,因为这些关节已经可以很好的代表一个姿势了,一般是左右脚和尾椎骨,也可以根据需要添加,如荣耀战魂中还添加了武器的骨骼。


速度Cost
和姿态Cost计算基本一样,直接对比动画数据即可。
轨迹Cost
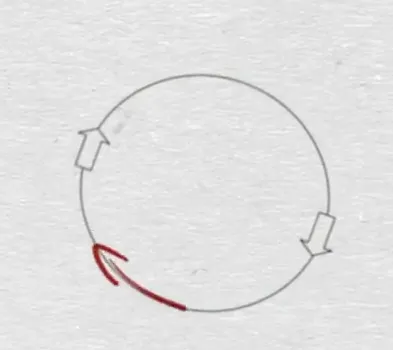
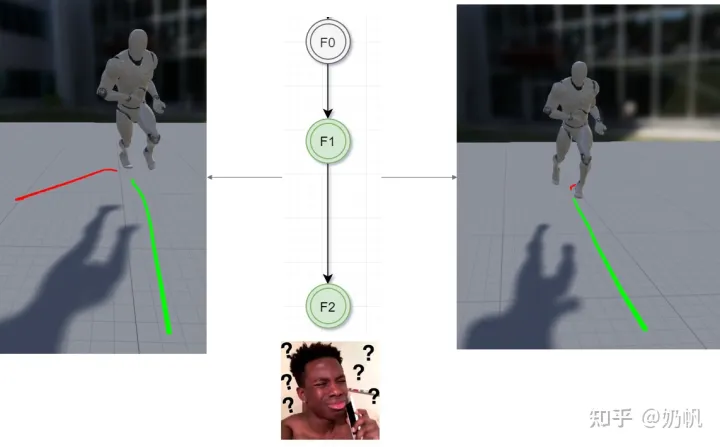
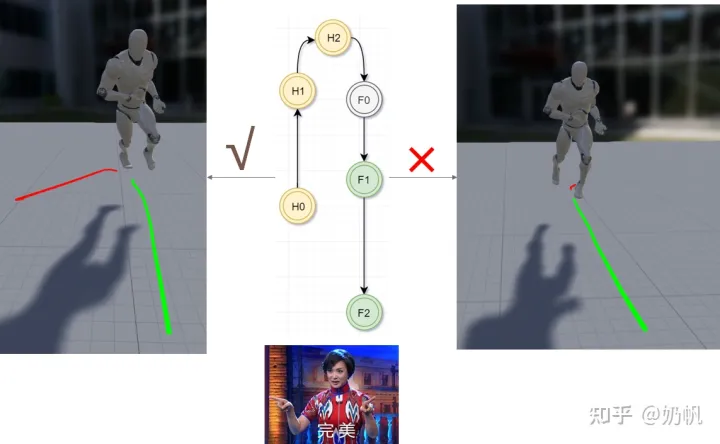
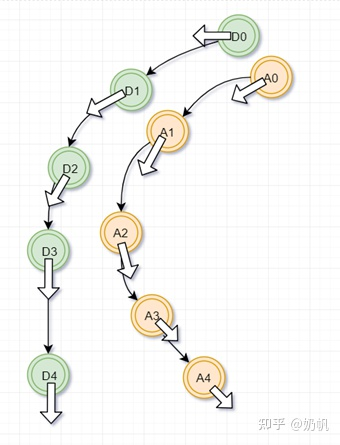
轨迹计算部分,育碧的源码考虑了未来几帧和过去几帧的位置和朝向,考虑未来的轨迹很好理解,为什么还要考虑过去的轨迹呢?如下图,有可能两个动作片段未来的行为一样,但是其过去不同,这时为了能更好的分辨出哪个动作片段更好,就需要引入过去的行为。
 |
 |
|---|
我们将计算的这些位置和朝向信息的Cost相加就是最终的Cost
 |
 |
|---|
Motion Matching的优化问题
- 提前计算特征
- 惯性化过渡
- 镜像数据表
- LOD
- KD-Tree
- 无需每帧都去寻找最优动画
因为如果用户没有改变输入,角色一直向前走,只需要从当前动画帧继续向后播放即可。
可以发现,由于Motion Matching算法本身就是一个搜索算法,不论如何加速,都需要将数据库中的数据放入内存,而Motion Matching实现动画过渡真实自然的基础就是很大的动作数据库,因此Motion Matching对内存的占用很大,这也是限制其在移动端大量应用的原因。
Learned Motion Matching

为了减小内存占用就要在Motion Matching实现过程中去除对动画数据库的依赖。Learned Motion Matching基于传统Motion Matching,用神经网络代替动画数据库,在实现了很好的动作效果的同时,大大降低了内存占用。
|
|
|---|
传统Motion Matching
首先我们先回顾一下Motion Matching:
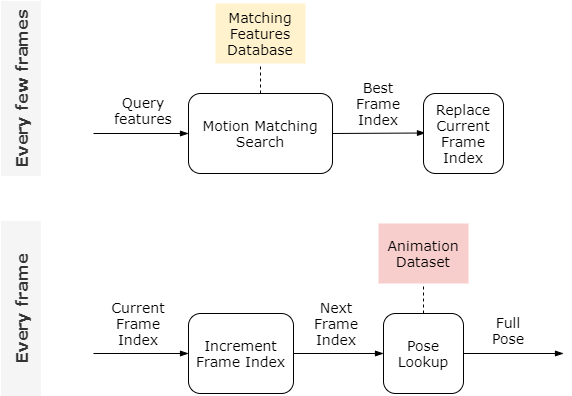
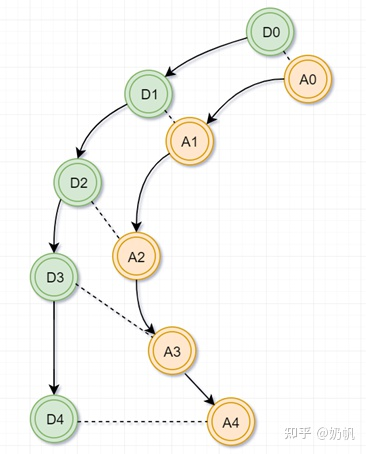
动画片段是由一系列的姿势(full poses)组成的,每个姿势有一个帧序号(frame index)指出这个姿势在动画数据库中的位置,向后播放动画意味着每帧增加frame index并且从动画数据库中找到对应的姿势,每隔几帧做一次利用特征序列(当前姿态信息和由输入估计的轨迹)和特征数据库(提前计算好的动作特征)做对比实现的动作匹配搜索(Motion Matching Search),得到的最匹配的动画帧替换当前帧,作为下一帧继续播放。
代替动作数据库
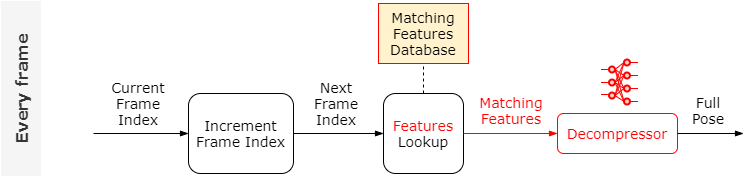
首先尝试去除对每帧进行的访问动作数据库的依赖,将直接去动作数据库中寻找动作替换成去特征数据库中寻找特征,找到的特征作为一个叫做Decompressor(可以理解为将动作特征解压成完整的动作)的神经网络的输入,由这个神经网络得到完整的姿势(这里是可行的,作者Daniel Holden的另一些工作PFNN就是尝试生成动作)

图中灰色的是直接访问动作数据库生成的,橙色的是Decompressor生成的,可以看到动画效果几乎没有区别,但是仔细观察骨骼的手部,发现还是有差异,这是由于特征不足引起的,我们可以添加更多的特征,但是我们可以用另一个神经网络自动找到这些额外的特征:
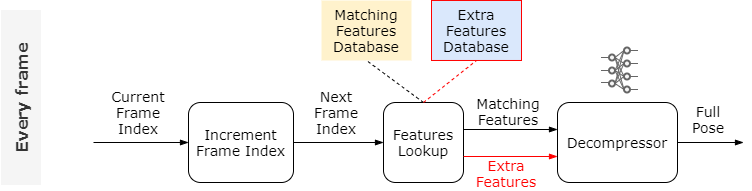
添加了这个网络之后,动作质量更高了。

当去掉了对动作数据库的依赖之后,内存减少了很多: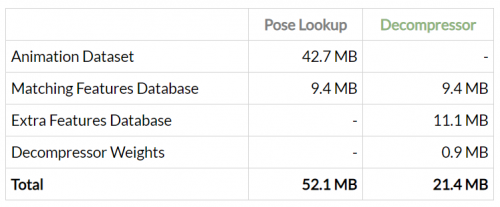
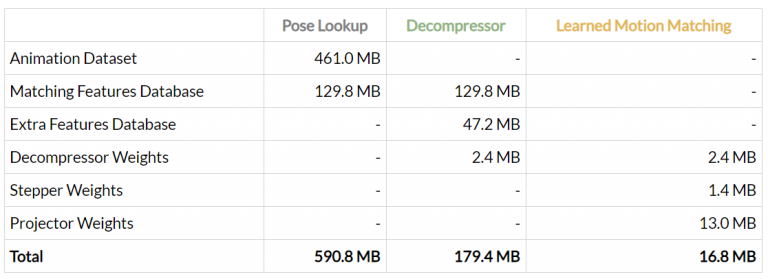
经过以上优化之后,整个过程如下图,但这时这两个特征数据库实际上还是随动作数据库的增大而增大,如果我们的动作数据库足够大,这两个特征数据库也会占用很大的内存。
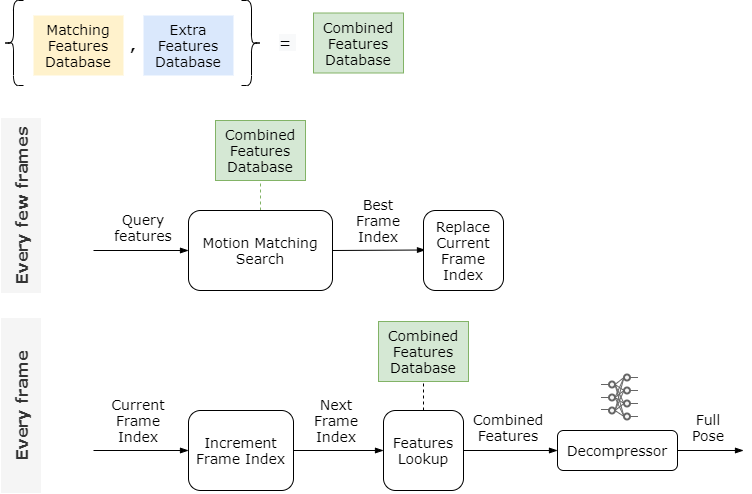
下一步尝试在每一帧摆脱对特征数据库(Combined Features Database)的依赖。
代替特征数据库
首先代替每一帧中的Feature Lookup,如果可以将每一帧的输入换成特征数据(当前动作的特征),可以训练一个神经网络叫做Stepper输出下一帧的动作特征,由于我们每隔几帧就会进行Motion Matching Search,因此这个Stepper网络只需要预测出之后很短一段时间动作特征的变化。此时整个逻辑如下:
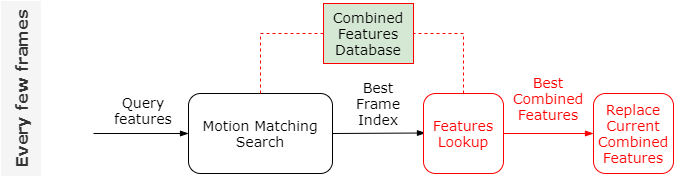
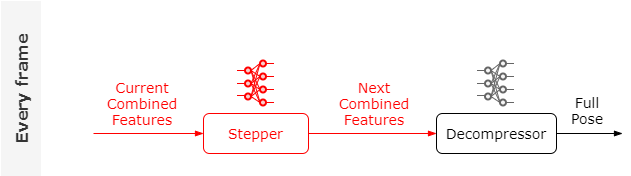
最后我们再训练一个神经网络Projector,用来直接预测与当前输入特征最匹配的特征:
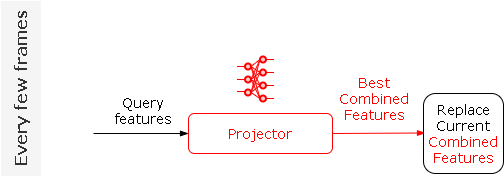
最终的整个Learned Motion Matching过程如下: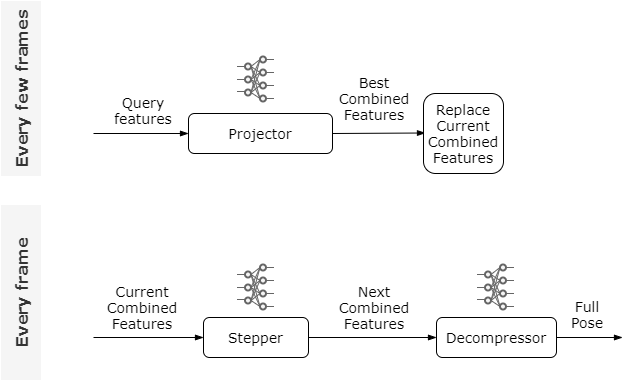
现在的内存比较: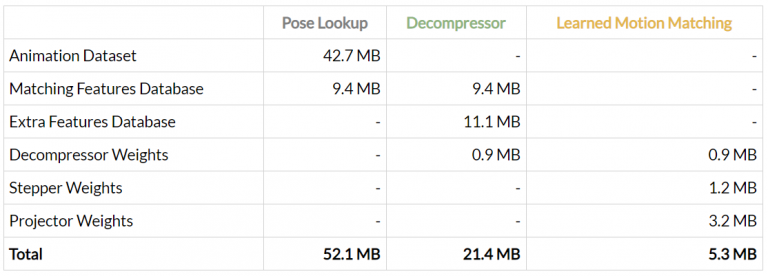
参考资料
GDC2016-Motion Matching
introducing-learned-motion-matching 中文翻译:Motion Matching的发展回顾
简单聊聊Motion Matching
Games105-计算机角色动画-06
2018GDC-Character Control with Neural Networks and Machine Learning