C++Review-How C++ Works
复习C++
主要参考 Cherno’s C++ 教程
C++从文本到程序
我们编写的代码本质就是文本(text),要让这个文本变成机器可以执行的应用(binary),需要有两个主要的操作:编译(compiling)和链接(linking)。
当我们按下编译键(ctrl+F7)时只会进行编译,按下build键时会先编译后链接。
C++编译器(Compiling)
C++编译器的工作是将文本(.cpp文件或者.h文件)转换为obj文件,也就是机器语言。
说到底就是编译器把代码转化为constant data或者instructions
编译的基本步骤
- 需要预处理(pre-process) 代码,处理所有的预处理语句(preprocessor)
- 编辑解释(tokenizing)和解析(parsing),将c++文件里的这些文本翻译成编译器可以理解和处理的语句
结果就是创建抽象语法树(abstract syntax tree) - 根据这颗抽象语法树产生cpu真正执行的机器码
编译单元(translation unit)和文件的关系
C++不关心文件(file),是什么文件对编译器来说并没有硬性要求,编译器会默认cpp文件是C++文件,h文件是header文件,但是这只是默认,完全可以自定义另一种文件.cherno文件是C++文件,编译器就会将cherno文件当作C++文件处理。
一个编译单元(translation unit) 对应一个obj文件,一般都是每个文件是一个编译单元,但是如果使用了#include,将别的文件包含在当前的文件中(本质就是创建了一个大的cpp文件,里面有很多cpp文件),且只编译当前这个文件,那么这个文件和他include的文件组成一个编译单元,也就只会得到一个obj文件。
预处理(pre-process)
#include的工作原理就是找到你include的文件,之后复制其全部内容到当前的文件。
#define的工作原理就是用anything替换INTEGER
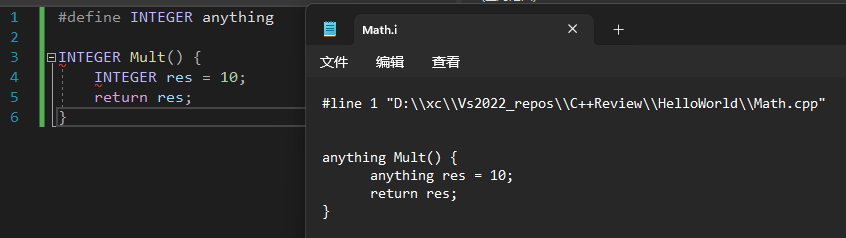
Math.i是生成的预处理文件,可以在项目属性里设置生成预处理文件,但是这样VS就不会生成obj文件了。
obj文件
obj文件就已经是机器码了:
如果选择了优化,在编译阶段就会对代码进行优化,比如删掉未使用的代码,计算所有的常量,删掉多余的寄存器等等。而为了使Debug方便,VS在Debug模式下默认禁止代码优化,就导致其运行起来较慢。
C++链接器(Linking)
当我们将每个编译单元编译成一个Obj文件之后,这些文件是独立的,并不能进行交流,而我们经常将不同的代码写在不同的文件中,因此我们需要链接(Linking),将这些独立的Obj文件联系起来。就算我们将所有的代码都写在一个文件中,我们也需要告知程序的入口(main函数)在哪,也需要链接操作。
常见的链接错误
- unresolved external symbol(未解决的外部符号):链接器找不到他需要的东西
- one or more multiply defined symbols found(重复定义):链接器不知道选择哪个
常见于include头文件时,可以使用static,inline或者移动函数定义的方式(关键点就是理解include实际上就是复制粘贴!)
VS设置
Output
输出目录:$(SolutionDir)bin$(Platform)$(Configuration)\
中间目录:$(SolutionDir)bin\intermediates$(Platform)$(Configuration)\
可以使结构清晰,方便查找。
Static关键字
在类或结构体外
类外的static修饰的符号在link阶段是局部的,也就是说它只对定义它的 编译单元(.obj) 可见。
当链接器(Linker)工作时,他不会找static修饰的变量,如果不是static修饰的全局变量,在link阶段就会随着链接而变成一个“整个项目的全局变量”,因为每一个使用到这个全局变量的编译单元都会去其他编译单元中寻找这个全局变量,如果不同的编译单元中定义了命名相同的全局变量,就会在链接阶段报重复定义的错。
假如在头文件中定义static变量,之后在不同的cpp文件中#include这个头文件,那么其实这些不同文件中的变量是相互独立的(因为#include就是复制,相当于分别在不同的文件中定义了static变量)
extern
extern表示其修饰的变量或函数需要在其他编译单元中寻找。
因此:尽量让所有的全局变量和全局函数都被static修饰
在类或结构体内
类内的static修饰的符号表示这部分内存是这个类的所有实例共享的,静态方法(static method)不能访问任何非静态的变量或方法(因为类内的static只会被实例化一次,也可以理解为静态方法没有类实例,它并不能得到当前被实例化对象的信息),类中的非静态方法之所以可以访问类中的变量是因为有个隐含的参数:this指针,而静态方法没有this指针,就当然不能访问非静态的成员了。
1 | |
static关键字使用场景
- 作用域是局部作用域,生命周期是整个程序的生命周期
1
2
3
4
5void function(){
static int i = 0;
i++;
std::cout<< i <<std::endl;
} - 单例模式(只有一个实例)
1
2
3
4
5
6
7
8
9
10
11
12class Singleton{
public:
static Singleton& Get(){
static Singleton instance;
return instance;
}
};
int main(){
Singleton::Get();
return 0;
}
const关键字
Cherno把const称为一个假的关键字,因为它并不会对产生的代码造成什么实质上的影响,它只是一种 承诺 ,承诺这是一个不会被改变的常量,用来方便编程。
const常见用法
- 定义常量
1
const int MAX_SPEED = 50; - 定义指针本身是常量还是指针指向的内容的常量
1
2
3
4
5
6
7
8
9
10
11
12
13int* aPtr = new int(2);
/*-------------------------------------*/
const int* p0 = new int; // p0指针指向的内存存的是不可改变的常量,等价于:int const* p0 = new int;
*p0 = 2; // 报错
p0 = aPtr; // 正确
/*-------------------------------------*/
int* const p1 = new int; // p1指针指向的内存地址是不可改变的
*p1 = 2; // 正确
p1 = aPtr; // 报错
/*-------------------------------------*/
const int* const p2 = new int; // p2指针指向的内存地址不可改变,内存地址中的量也不可改变
*p2 = 2; // 报错
p2 = aPtr; // 报错 - 定义类中的方法,承诺这个方法不会修改变量(const只能修饰类中的方法)
1
2
3
4
5
6
7
8
9
10class Entity{
public:
int m_X, m_Y;
int GetX() const{
return m_X;
}
void SetX(int x){
m_X = x;
}
};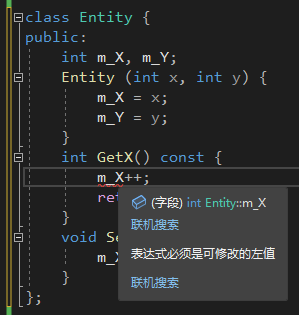
const如果只是一个承诺那它是不是没什么实际的用处呢?当然不是!按照下图,GetX()必须用const修饰,因为函数Print(const Entity& e) 的参数是一个常引用(类比上面的const int* p),意味着其引用的对象(也就是自身,因为引用只是一个别名)是一个常量,那就要确保在函数中不能对自己这个常量进行修改,就只能调用被const修饰的函数。
因此,如果没有修改类或者不应该修改类时,总是把这个方法标记为const!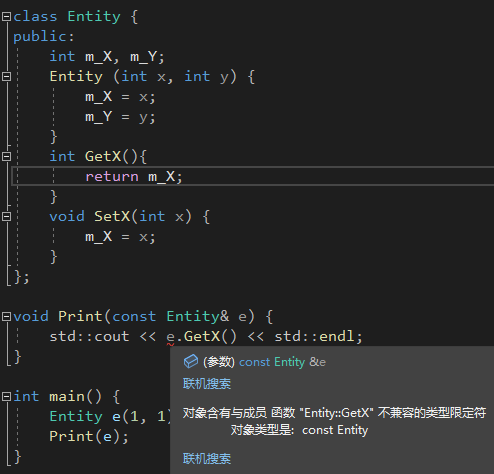
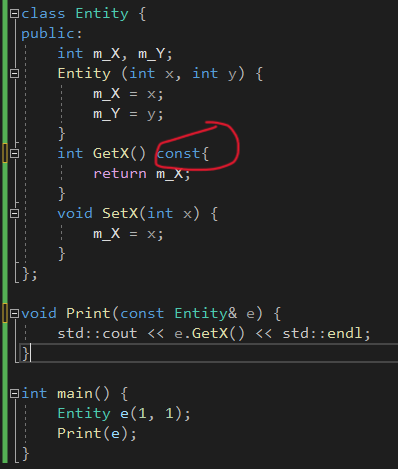
尽量总是使用 “const引用” 作为函数参数!,否则会默认复制一个变量,造成性能浪费。
1 | |
inline
相当于把内联函数里的内容写在调用函数处;
相比于宏,多了类型检查,真正具有函数特性
枚举
枚举类型
枚举类型本质就是整型,下面的LevelError,LevelWarning,LevelInfo值就是0,1,2;因此枚举也可以直接进行整型的大小比较。
1 | |
构造函数
总是使用构造函数初始化列表!,不使用函数初始化列表会导致一些变量(比如下面的m_A)被初始化多次,造成性能浪费。
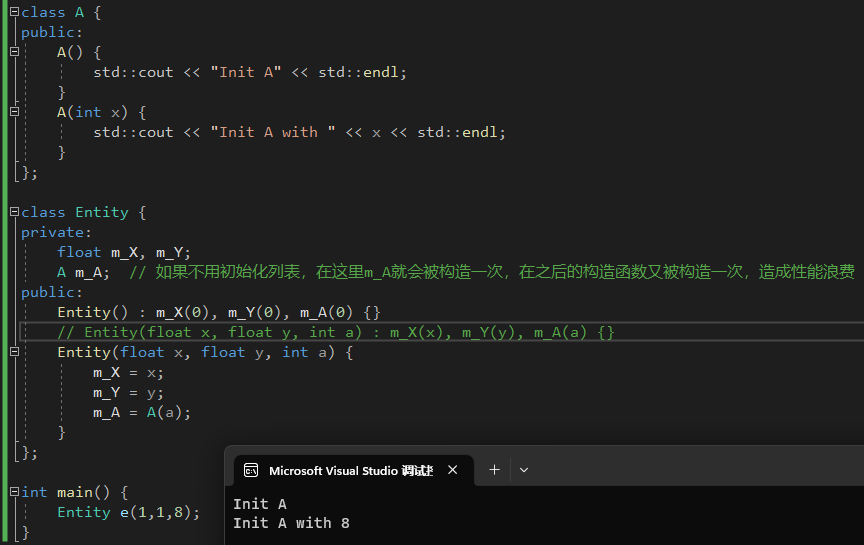 |
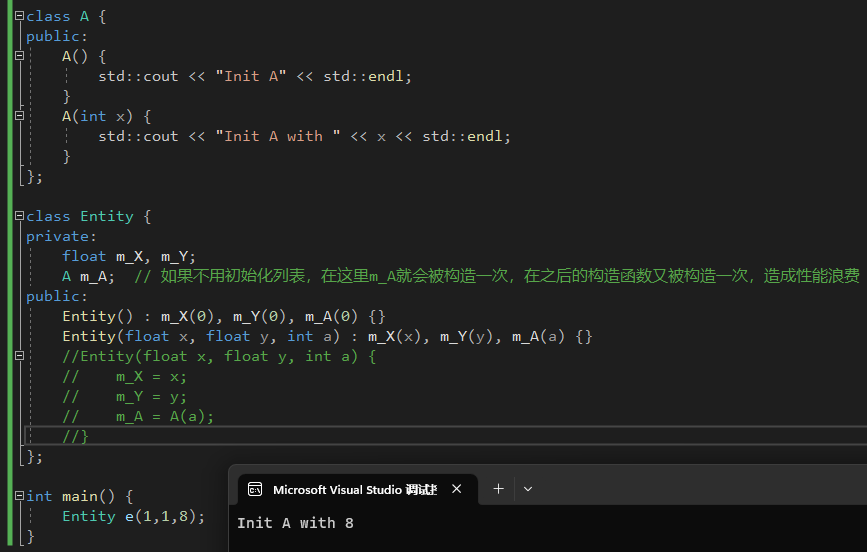 |
|---|
继承
继承的基本写法:
1 | |
Player类不仅是Player类,它同样是一个Entity类。我们可以在任何想要使用Entity的地方使用Player(多态)
虚函数
虚函数一般通过 虚函数表(vtable) 来实现编译,在编译阶段通过查询虚函数表确定该函数的定义。
在c++11中允许用 override 标注被重写的虚函数,增加代码可读性。
1 | |
纯虚函数(接口)
纯虚函数的本质和其他语言中的接口相同,它是一种特殊的虚函数,在父类中不需要实现,而在子类中必须实现。
包含纯虚函数的类不能被实例化,因为纯虚函数没有被定义。只能实例化一个实现了所有纯虚函数的类。
1 | |
操作符和操作符重载
操作符本质就是函数。
1 | |
堆(heap)和栈(stack)
C++中的堆和栈都指的是内存,在栈上的变量占据的内存会被自动回收(当变量生存周期结束时),在堆上的变量占据的内存不会被自动回收。
1 | |
智能指针(smart pointer)
当定义一个智能指针时,它会调用new分配内存,之后根据用的是哪个智能指针决定什么时候自动释放内存。
unique_ptr
unique_ptr是一个作用域指针,之所以叫unique_ptr是因为它是唯一的,不允许复制一个unique_ptr,因为当你复制之后就会出现两个指针指向同一片内存的情况,当一个unique_ptr死亡时它就会释放这片内存导致另一个unique_ptr指向一片被释放的内存。
1 | |
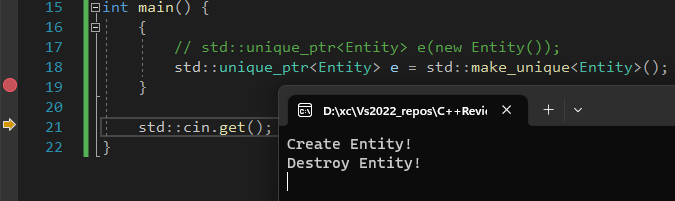
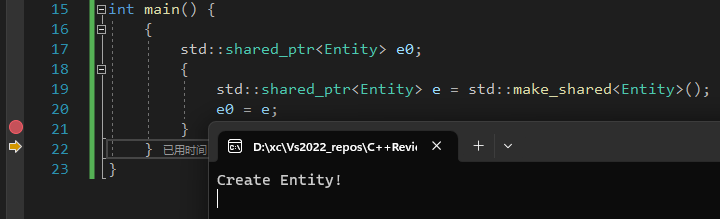
shared_ptr
shared_ptr和unique_ptr的区别就在于它允许复制,这是借助 引用计数(reference count) 实现的。当shared_ptr被复制之后,引用计数也会加一,当引用计数为0时,才释放内存。
1 | |
C++的复制和拷贝构造函数
尽量总是使用 “const引用” 作为函数参数!,否则会默认复制一个变量,造成性能浪费。
1 | |
浅拷贝
只会复制 “表面” 的内容,例如下面的代码,默认的拷贝构造函数只会复制这个类的成员(m_buffer和m_Size)而不会去复制m_buffer指向的内存。就会导致复制后的类实例中的m_buffer指针仍然指向原来m_buffer指向的内存,当析构函数调用时就会将同一片内存释放两次,程序崩溃;或者当要修改复制后的内容时连带原来的内容一起修改。
1 | |
深拷贝
与浅拷贝相对,在我们自己定义的类中需要重新写拷贝构造函数。
1 | |
- TCP和UDP
- 内存管理
- 进程线程(锁)
- 设计模式
- 右值
- 红黑树
- 渲染管线
- 渲染方程
- tcp三次握手四次挥手
- tcp和udp