骨骼动画相关技术概述
骨骼动画相关技术概述
本文结构参考游戏引擎架构(第二版)第11章 动画系统,专注与骨骼蒙皮动画。
3D动画早期使用刚性层阶式动画,将角色模型直接拆分成大腿、小腿、躯干等部分,直接控制这些部分旋转,但是这种技术会在关节位置产生缝隙。还有一种技术是每顶点动画技术,这种动画直接控制角色模型的全部顶点,效果很好但是需要储存全部顶点,在实时游戏中几乎无法使用。变形目标动画(morph target animation)与顶点动画类似,但是只存储少量极端姿势(extreme pose)在运行时进行混合,常用于面部动画。
蒙皮动画兼具了刚性层阶式动画和顶点动画的优点,通过蒙皮技术实现,每个骨骼控制一些顶点的移动,在制作动画时只需要控制骨骼的移动即可,是现在最常用的3D动画技术。
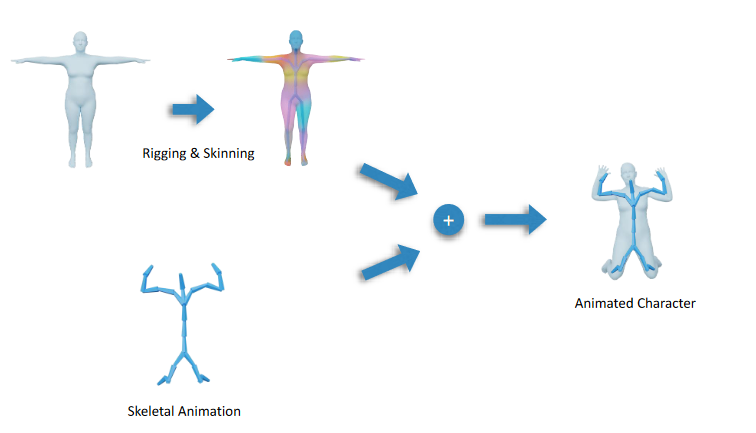
骨骼与姿势
骨骼(skeleton)由骨头(bone)组成,骨头几乎只指关节(joint),因为骨头是刚体几乎不会改变形状,动画师通过直接控制关节构造一个个姿势(pose),这些姿势连续播放就形成了动画。
骨骼层级结构
骨骼都有一个根(root),所有的其他骨头都是这个根骨的子物体: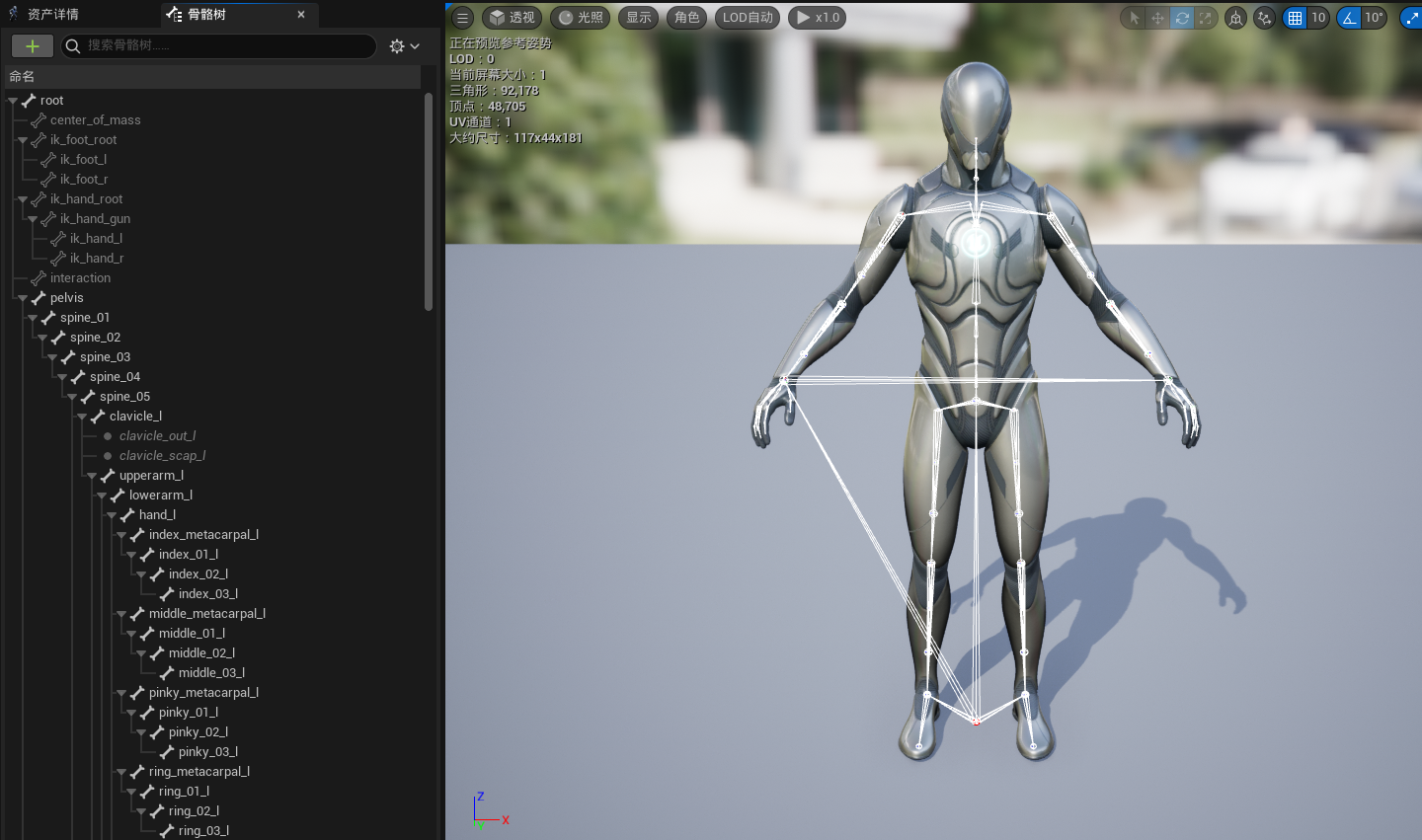
典型的骨骼数据结构:
bones或joint中存储了骨骼的名字,绑定姿势的逆变换(将模型坐标转换到该骨骼下的局部坐标,这里存储为4*3的矩阵应该是为了节省存储空间,因为最后一行为(0,0,0,1)),父索引(索引可方便查找和存储)。
姿势
把角色摆出各种姿势,插值并播放就产生了动画,每个姿势由每个关节的 SQT(scale,quaternion,translation) 表示。
 |
 |
|---|
绑定姿势
一般为 T-pose 或 A-pose,表示网格绑定到骨骼上时的姿势,也叫参考姿势(reference pose)或放松姿势(rest pose)。
 |
 |
|---|
局部姿势
最常见的关节姿势是相对于父关节来指定的,有时使用局部姿势描述相对于父关节的姿势,即关节局部坐标中的 SQT 变换。
全局姿势
全局姿势指将关节姿势表示为模型空间或者世界空间,通过从该关节遍历至根关节并乘上每个关节的局部姿势算出。全局姿势在计算蒙皮矩阵时需要,一般存储在上面的关节数据结构中的绑定姿势的逆变换。
每个关节的局部姿势就是局部坐标系,局部姿势的变化就是局部坐标系的变化,因此参照基变换的概念,可有如下结论,即乘上局部姿势(局部坐标系的基)可以将局部坐标转换到全局坐标(参照3Blue1Brown的线性代数的本质基变换章节)
蒙皮绑定
每个顶点一般绑定至4或4的倍数个关节,其数据结构为:
这里的position是模型空间(废话…)
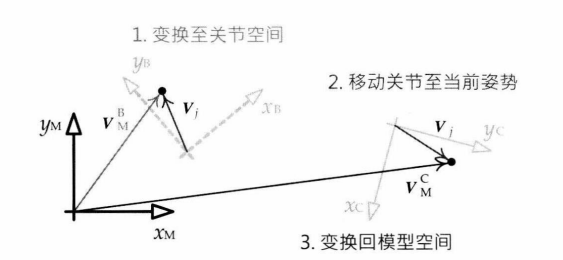 |
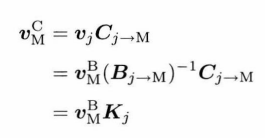 |
|---|
蒙皮可以使顶点跟随骨骼移动的原理如上图所示,先将顶点转换至绑定到的关节空间,因为关节移动时,顶点相对于关节的位置不变,移动关节之后可以将顶点再转换回模型空间,就完成了顶点在模型空间的移动。
线性混合蒙皮(Linear Blend Skining)
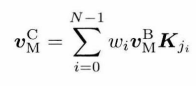
对每个顶点来说,其被绑定到的每个关节对他的影响程度不同,设定每个关节的权重,就可以通过加权算出顶点受这些关节共同影响后的位置。这就是线性混合蒙皮(Linear Blend Skinning)
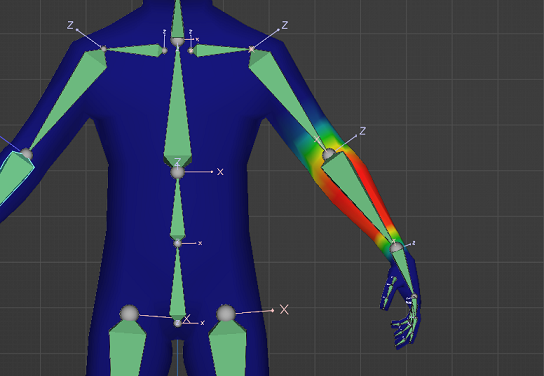
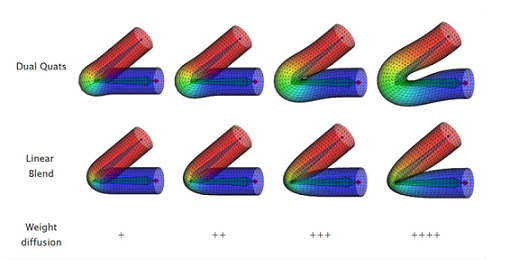
但是线性混合不能维持体积,会产生如下的Candy-Wrapper Artifact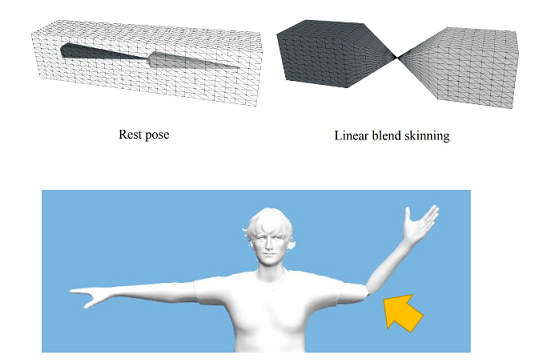
双四元数蒙皮(Dual-Quaternion Skinning)
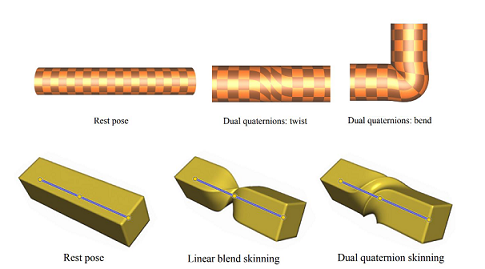 |
 |
|---|
如何解决LBS的问题
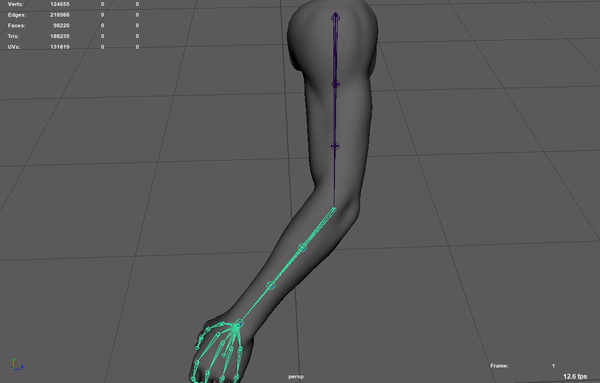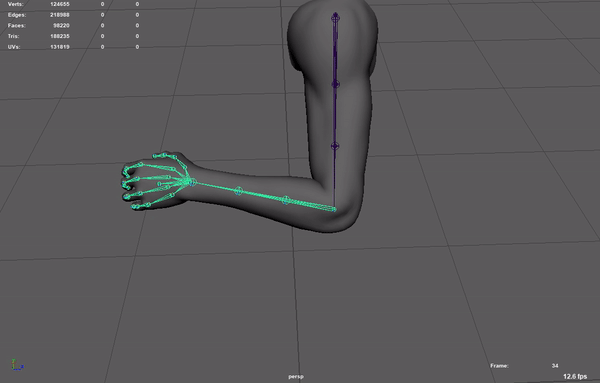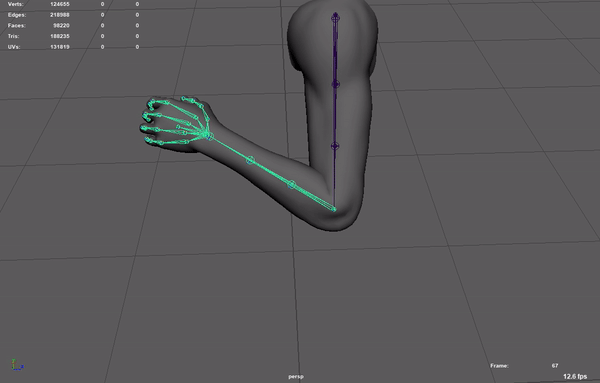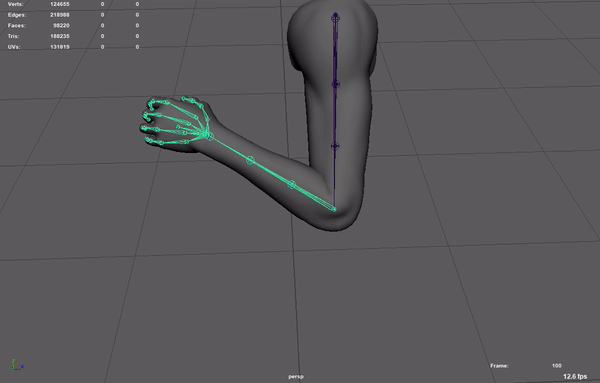
添加修型骨骼
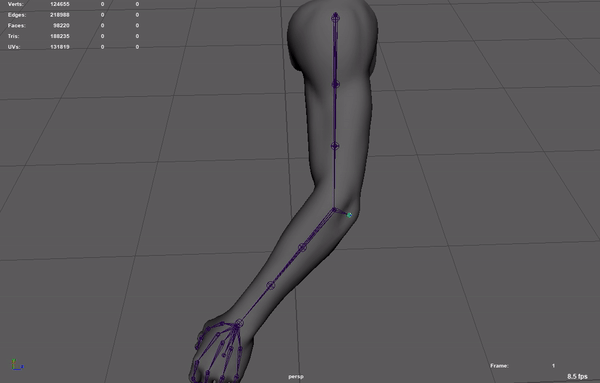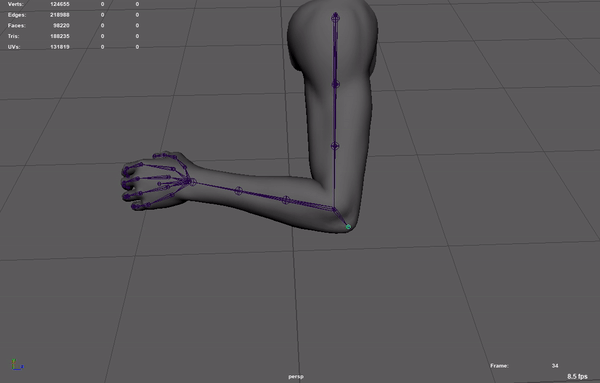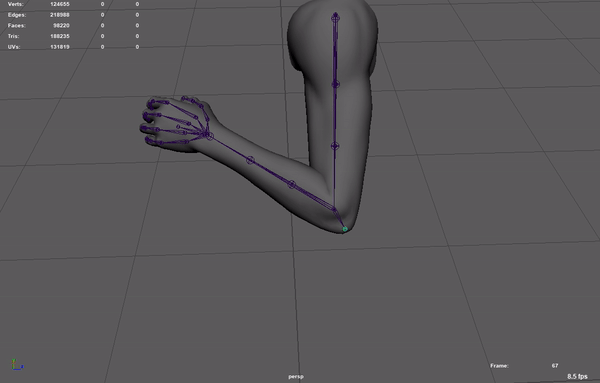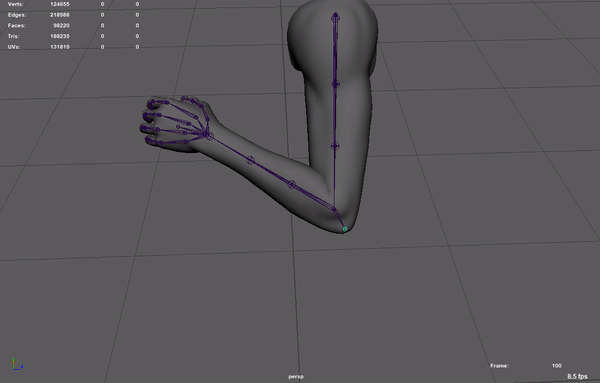
UE5的小白人就添加了许多修型骨骼,通过ControlRig实现修型。
 |
 |
|---|
使用blendshape (morph target)
对于对动画质量要求更高的3A游戏,添加再多的修型骨骼也较难达到模拟真实的肌肉运动,因此还是使用顶点动画的方法,建模师提前制作多个不同关节运动角度时的肌肉模型,之后在骨骼运动时读取这个结果。
如何驱动BS:
- 动画师手K
- JCM(Joint Controlled Morphs)骨骼驱动变形,等于Maya的PSD(Pose space deformations),用骨骼驱动morphs变形
- RBF驱动(之后详细讲)
PSD的相关技术文章:
Pose Space Deformation——从实践到原理再到实践
基于径向基函数的Pose Space Deformation
同时还需要考虑的问题是顶点动画开销太大,还是希望可以使用骨骼驱动,于是希望将blendshape通过某种方法烘焙到骨骼上,就有了蒙皮分解技术(例如SSDR-线性蒙皮分解)
蒙皮分解(蒙皮动画的逆运算)
假如有全身所有顶点的每帧的位置信息,能不能反过来推算出如果使用骨骼动画如何达成同样的效果。即假设我们给定骨骼数量,那么能不能推算出骨骼每一帧应该在什么位置,旋转如何(骨骼的全局姿势),以及每一个顶点应该绑定哪根骨骼,权重是多少。
|
|
|---|
SSDR是一个优化问题,输入是所有顶点的动画(每一帧来看就是所有顶点的模型空间的坐标),需要拟合出蒙皮计算公式中的 顶点蒙皮权重,$C_{j \to m}$(每帧的全局姿势)
原论文:Smooth Skinning Decomposition with Rigid Bones
知乎-线性蒙皮分解(SSDR)
ML Deformer (拟合morph target)
SSDR归根结底还是想通过LBS来驱动顶点,但是有一些复杂的BlendShape不是线性变化的,不能用LBS驱动,这种方法解算出来的结果也就不太理想了。于是有了专门针对与BlendShape的拟合方法。
MetaHuman Framework & Machine Learning for Next-Gen Character Deformation | GDC 2023
UE5 机器学习变形器解析
UE5推出的新功能ML Deformer借助Deformer Graph和机器学习完成对复杂的非线性顶点运动的拟合,比如肌肉模拟和布料模拟。工作流程如下:
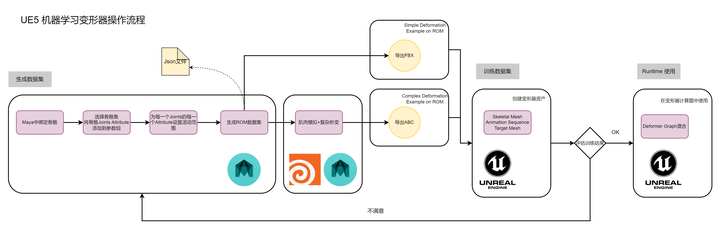
首先在Maya中完成绑定,使用UE官方提供的Maya插件设置每个关节的活动范围限制,之后生成随机动作(ROM-Random of Motion),之后在Houdini中用离线的方法进行肌肉模拟并生成 abc文件(顶点动画),在UE中训练。。
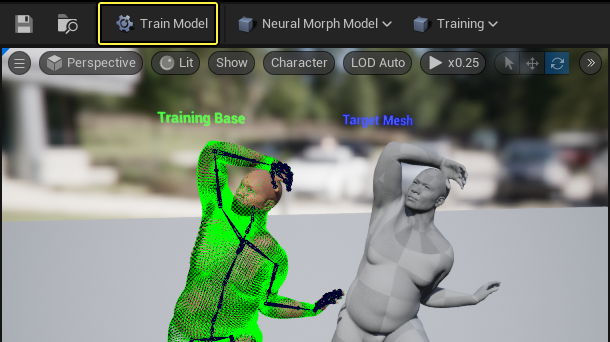
下图左侧模型身上的绿色信息就是使用LBS蒙皮的模型和Houdini中模拟出来的模型的顶点坐标的差值,这些差值被提供给神经网络,经过训练,更新原本LBS蒙皮的权重来拟合肌肉模拟的结果。
自动蒙皮
Siggraph2021: Learning Skeletal Articulations with Neural Blend Shapes 类似ML Deformer?
Siggraph2019: NeuroSkinning: Automatic Skin Binding for Production Characters with Deep Graph Networks
动画混合
线性插值混合
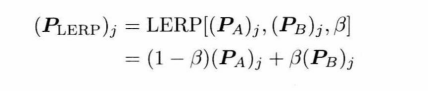
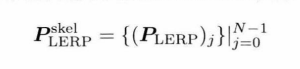
在线性插值时,直接对于矩阵插值不可行,因此一般对 SQT 格式的局部姿势插值,其中尤其注意对旋转的插值,一般使用四元数LERP 或 SLEAP(球面线性插值)
下面列举几种线性插值混合的应用
淡入淡出
淡入淡出是为了解决不同动画片段间的过渡问题,防止动画出现跳变。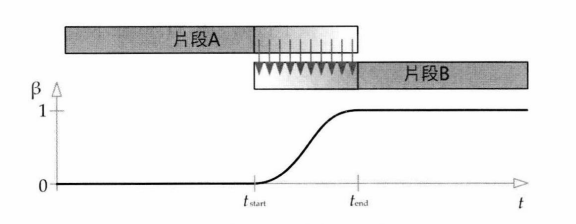
上图使用贝塞尔曲线的混合因子,可以达到更好的淡入淡出效果。
惯性化插值
2018GDC: Inertialization-High-Performance-Animation-Transitions
惯性插值-优异的动画过渡算法
UE5文档-惯性化
经典的插值算法都需要两个片段(源片段和目标片段),在插值过程中,这两个片段必须保存在内存中,并且如果有在片段中存在其他复杂运算就会对性能造成很大的开销。在日常生活中,我们人体的动作过渡其实也不考虑之前的源动作是什么,而是直接过渡到下一个姿势。因此就希望有一种方法可以实现只考虑目标动作不考虑源动作的过渡方法。
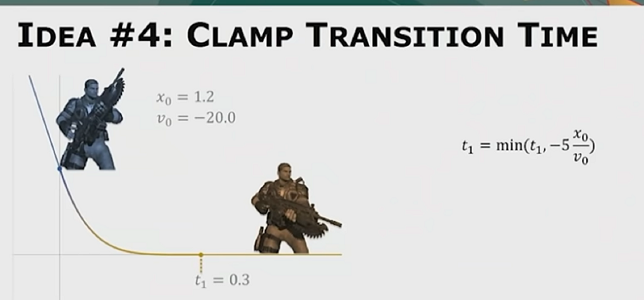
惯性化过渡不考虑源动作,只需要记录源动作最后一帧的变换,速度,加速度等值,利用五次多项式(因为五次多项式可以保证加速度是连续的)直接拟合出过渡曲线。如果直接进行拟合当源动作速度过大时,会出现overshoot的情况,为此将 $t_1$ 时刻的 跃度(加速度的导数)设置为零,计算出不会发生overshoot的最小 $t_1$ ,将目标片段开始播放的时刻提前到 $t_1$ 之前。
 |
 |
|---|
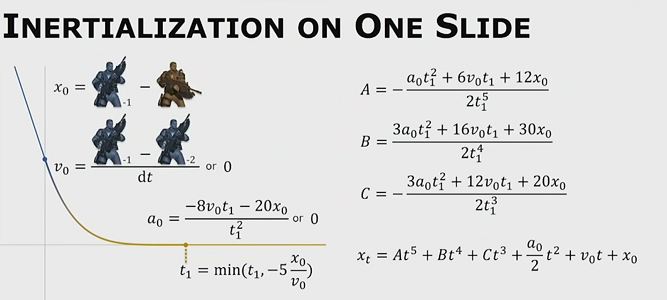
动画片段的过渡一般都是向量和四元数间的变换,因此在拟合过渡曲线之前还需要对向量和四元数做处理,将其都转换为标量。这里将向量的方向和大小分开,将四元数的旋转轴和角度分开:
 |
 |
|---|
在UE5中已经支持惯性化过渡,在状态机切换,混合节点,分层动画都可以设置一个惯性化请求,在最后输出动作之前添加惯性化节点。
 |
 |
|---|
骨骼分部混合
在线性插值混合时,屏蔽部分关节,不进行线性插值即可。一般需要创建一个遮罩,在unity中的Avatar Mask(混合模式为override)
但是这种方法太过生硬,因为一般人类不可能只有一部分关节移动,这些关节的移动都会带动全身移动,单纯进行骨骼分布混合无法实现这种效果。
加法混合
加法混合的原理是记录从参考姿势到 “加法片段”(也叫“区别片段”) 的变换,再把这个变换应用到其他需要进行加法混合的片段上,就可以实现很多有趣的姿势和动作变换,例如:将表示疲惫的加法片段应用于跑步片段就可以得到疲惫地跑步地动画。在unity中的Avatar Mask(混合模式为additive)
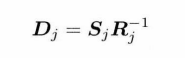 |
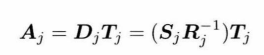 |
|---|
$D_j$ 表示区别片段,$S_j$ 表示来源动画(也就是例子中的疲惫状态的动画),$R_j^{-1}$ 表示参考姿势的逆变换(D=S-R用矩阵表示减法就是乘逆矩阵), $A_j$ 表示经过变换后的结果动画(疲惫地跑步), $T_j$ 表示需要被应用的目标动画(跑步动画)。
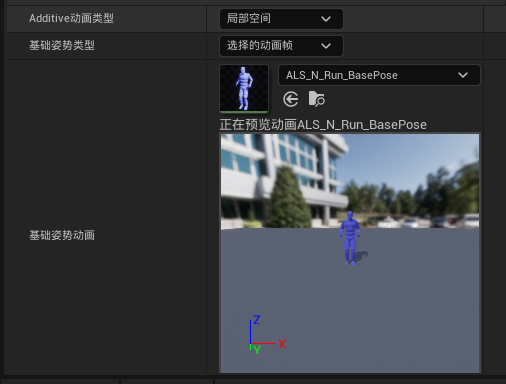
上图为在虚幻引擎中叠加动画的设置,这里需要选择的基础姿势就是参考姿势,该叠加动画就是来源动画和该参考姿势的 “差值”。
叠加动画类型分为:局部空间(Local Space) 和 网格体空间(Mesh Space),他们的区别在与网格体空间可以保证无论当前骨骼的朝向如何,应用叠加动画之后的结果和网格体空间下的结果一致: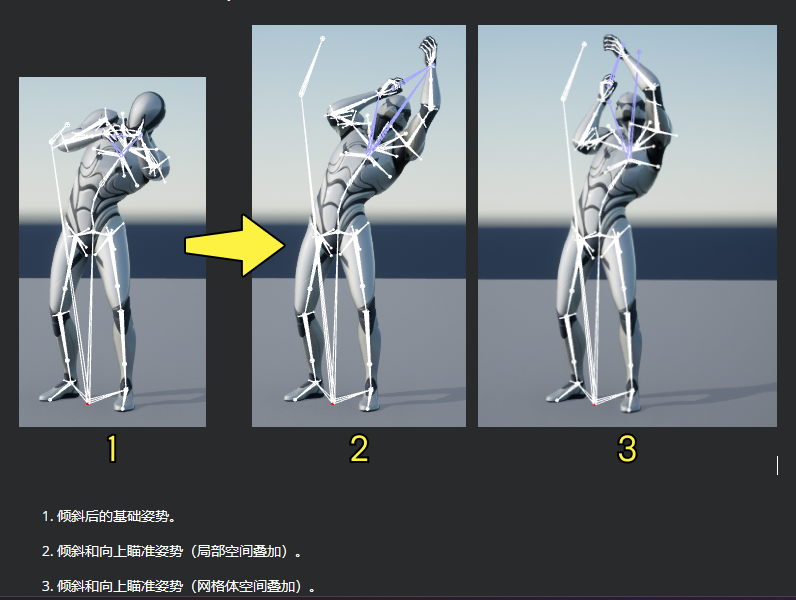
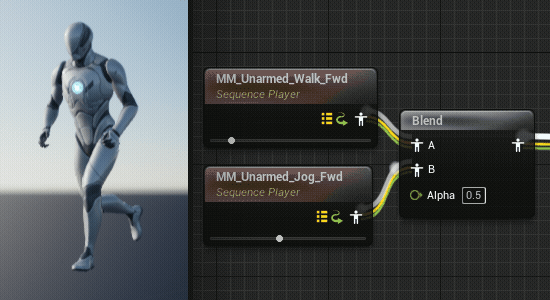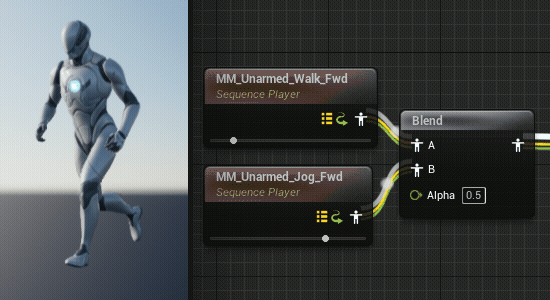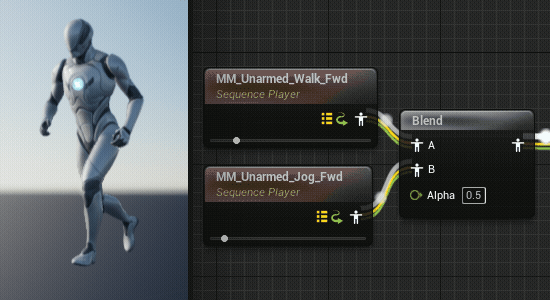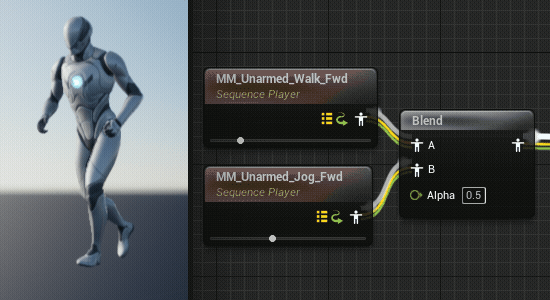
动画片段混合中的同步问题
在混合不同的动画片段时,由于动画片段的长度不一定相同,就会导致某些时刻的混合很不自然,在角色行走到跑步的过渡中尤为明显。(UE5的混合空间似乎自动进行了同步)
 |
 |
|---|
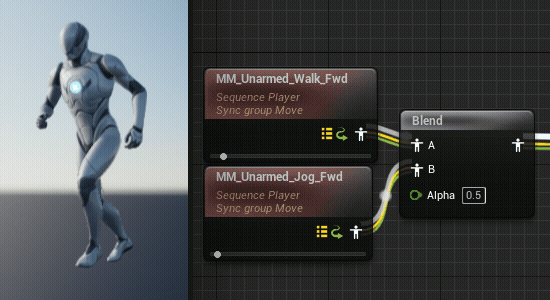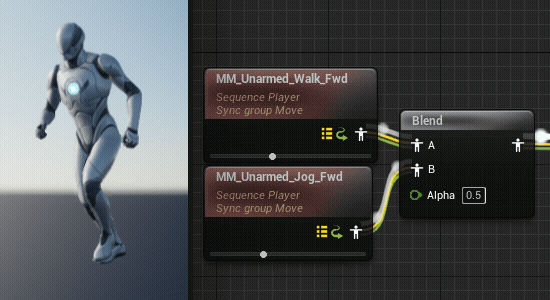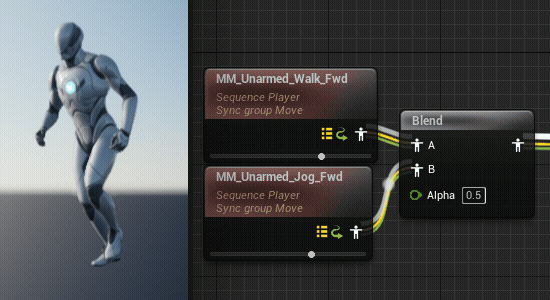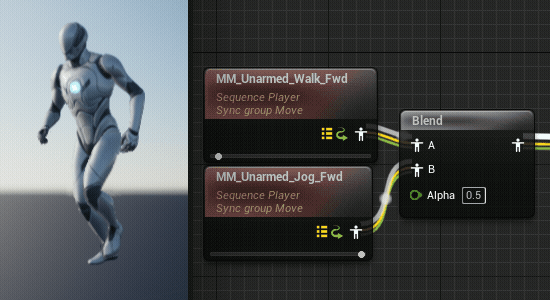
通过同步组可以将两个动画片段的长度变成一样的,可以消除这种不自然感(但是就要注意正在混合的两个片段需要有相似的步态以确保脚步的一致,比如走路和跑步都是先迈左脚并且脚接触地面次数相同)
或者使用同步标识,显式的标记左右脚: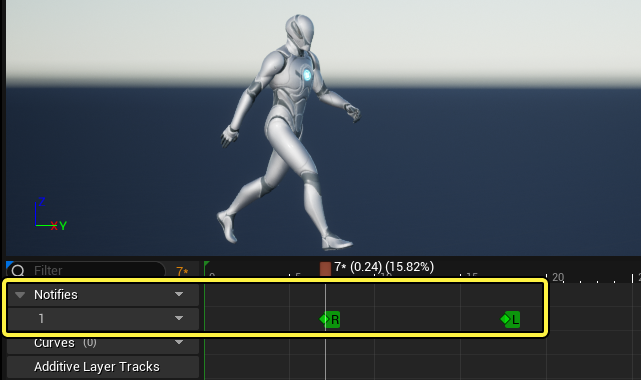
FK和IK
FK是Forward Kinematic 前向运动学,IK是Inverse Kinematic 逆向运动学,直观理解假如我们需要用左手拿一个苹果(假设可以拿到),FK需要我们指定从肩膀到左手的每个关节的旋转,IK则是直接将左手固定到苹果处,再计算我们的胳膊上的每个关节要如何旋转。IK可以看作一个优化问题
 |
 |
|---|
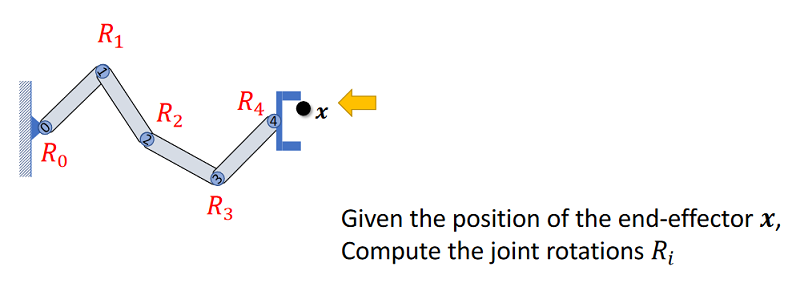
IK可能无解,可能有一个或多个解。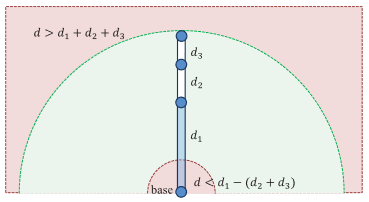
对于IK问题需要注意的有两点:
- IK问题有没有解
- 设置IK的终止条件,防止陷入无限循环
Two-bone IK
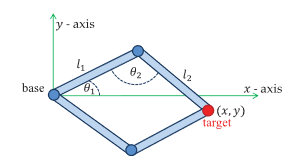
对于TwoBoneIK,可以使用解析法进行计算,由于三个点确定一个平面,所以需要增加一个控制点(也就是UE4中的PoleVector 极坐标点)来解三维空间内的旋转角度。
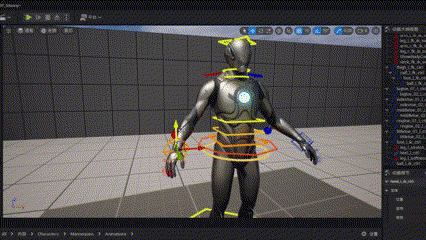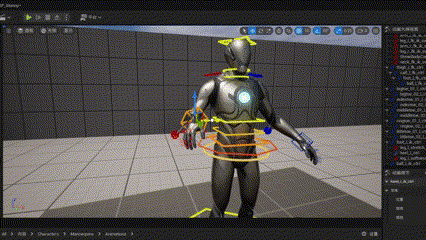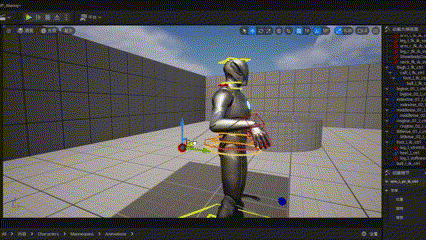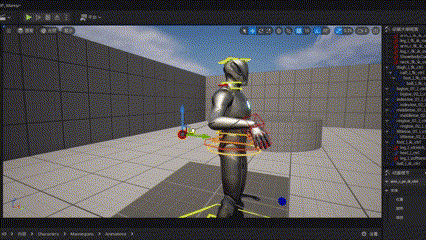
Unreal中的TwoBoneIK节点。
CCDIK
循环坐标推演(Cyclic coordinate descent)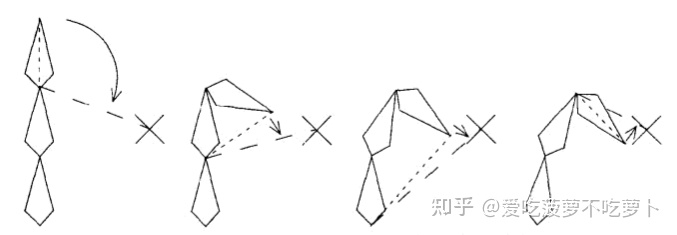
计算简单,只需要点乘叉乘,但其会有较强的倾向性,导致某些动作不自然,一般会对CCD添加约束。
雅可比逆矩阵法
比较复杂,是一种梯度下降的方法
FABRIK
Forward and backward reaching inverse kinematics(前向和后向到达IK)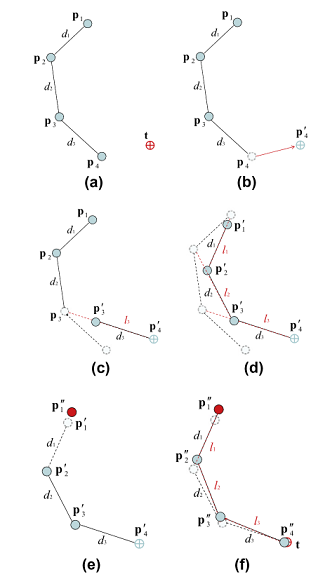
原理如图,看上去与CCD类似,但是FABRIK关注的是位置而不是旋转。FABRIK先从末端出发到达IK目标,依次反推回根节点,再让根节点到达初始点,依次反推至末端受动器,循环进行到终止条件即可。
FABRIK计算简单,并且适用于解决多个末端受动器的问题(如手指,双手指向同个目标),CCD和雅各比矩阵解决起来要困难一些。FABRIK只需要再sub-bases处计算平均值再向根节点迭代即可。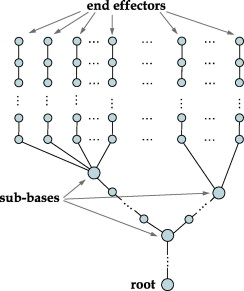
原论文:FABRIK: A fast, iterative solver for the Inverse Kinematics problem
动画重定向
 |
 |
|---|
Siggraph2020: Skeleton-Aware Networks for Deep Motion Retargeting
动画重定向技术是将一个角色的动画数据应用于另一个角色,使其看起来像是原始角色在执行相同的动作。最基本的动画重定向是当两套骨骼数目一致结构一致,把动画姿势与参考姿势的差异应用到目标骨架上。
实际应用:
- Unity中是利用Avatar将两套骨骼映射到同一套Unity自己定义的模板骨骼上
- UE中是允许手动设置骨骼的对应关系,UE5使用IK Rig建立约束关系的对应关系
数据驱动的角色动画
Phase-Functional Neural Networks for Character Control
参考资料
Games-105
建立下个时代的高清游戏美术资源生产管线(五):绑定篇-绑定基本概念
基于径向基函数的Pose Space Deformation
【游戏开发】逆向运动学(IK)详解
[合集] Data-Driven Character Motion Synthesis