百人计划-渲染路径
参考资料:
百人计划-延迟渲染管线介绍
【《Real-Time Rendering 3rd》 提炼总结】(七) 第七章续 · 延迟渲染(Deferred Rendering)的前生今世
延迟渲染
《Unity Shader入门精要》 第9章 更复杂的光照
代码标注为C++只是为了会有高亮好看,实际是ShaderLab
前向渲染(Forward Rendering Path)
前向渲染是指对每一个物体,先计算所有光源对当前物体的影响,再渲染下一个物体,同时,前向渲染是先着色,再进行深度测试的,导致许多光照计算由于最后不会显示在屏幕上而被浪费掉。前向渲染的主要缺点是,对于多光源场景,渲染效率较低,如有 n 个物体,m 个场景,需要进行 n*m 次光照计算。
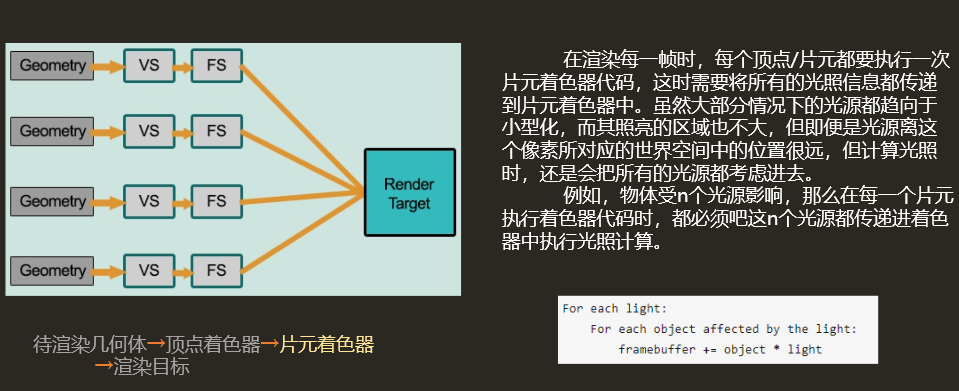
Unity中的前向渲染
在unity中想要使用前向渲染,需要设置:
1 | |
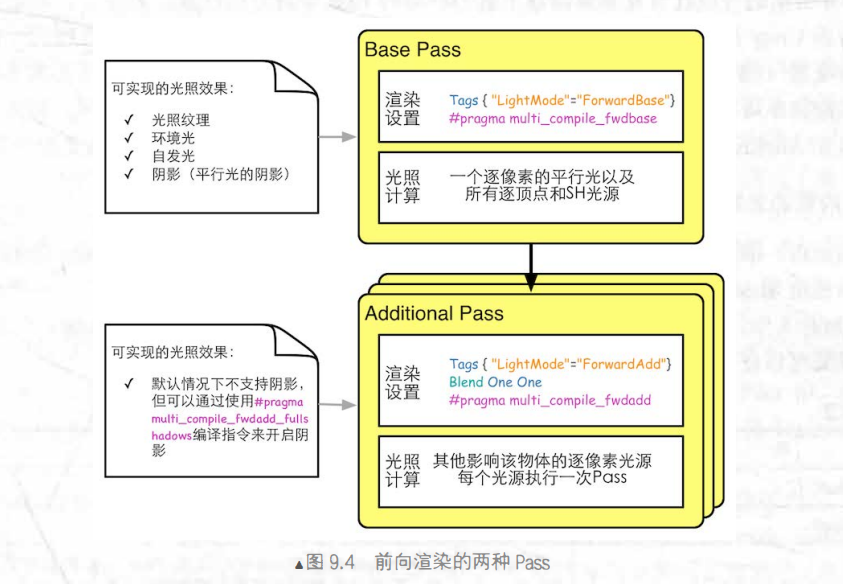
在unity内置管线中,前向渲染处理多光源时,一般使用两个Pass,Base Pass和Additional Pass,一个Base Pass只会执行一次,additional pass执行的次数和光源数量有关:
在URP管线中,前向渲染处理多光源被整合进单个Pass中,使用Lighting.hlsl中的函数实现:
1 | |
左侧为多光源shader,右侧为单光源shader
延迟渲染(Deferred Rendering Path)
延迟渲染是一种针对场景有大量光照时前向渲染效率不高的替代方案,由于前向渲染是先计算着色再进行深度测试,其中的每一个片元都要进行着色计算,造成了大量的性能浪费,延迟渲染就反其道而行之,先进行深度测试,再进行着色计算。
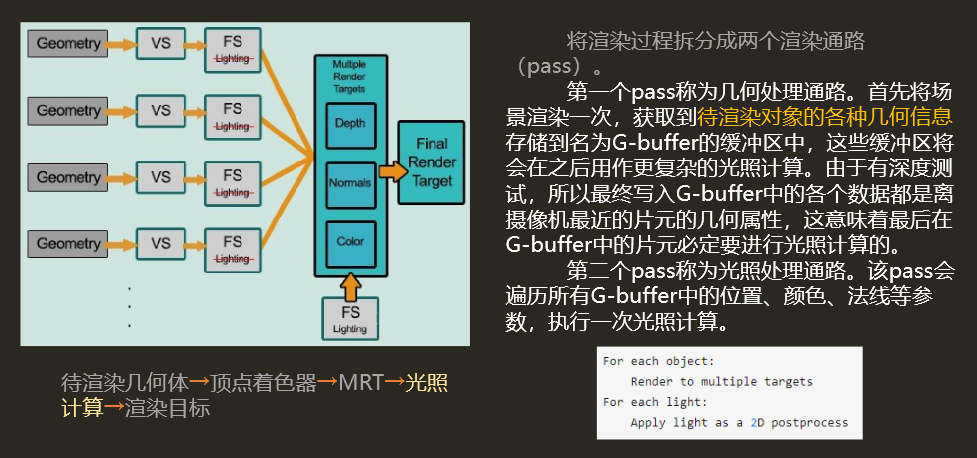
延迟渲染需要两个pass:
- 几何处理阶段:
在这个阶段,获取渲染对象的各种几何信息,并存储(渲染)到G-buffer中; - 光照处理阶段:
之后对屏幕上的每个像素,取出其G-buffer中的几何数据,进行光照计算;
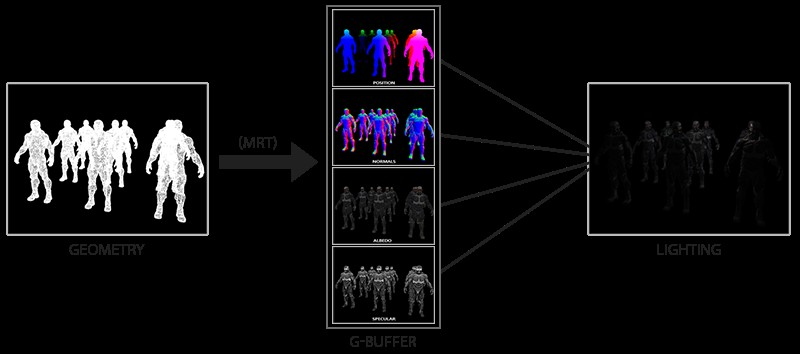
可以看出在延迟渲染中,最后进行光照计算的次数就是屏幕上的像素个数,这样就避免了光源过多时,光照计算次数也跟着变多的问题,并且保证了每一次光照计算都是有用的计算。
延迟渲染和前向渲染的对比
延迟渲染流程对比前向渲染流程:
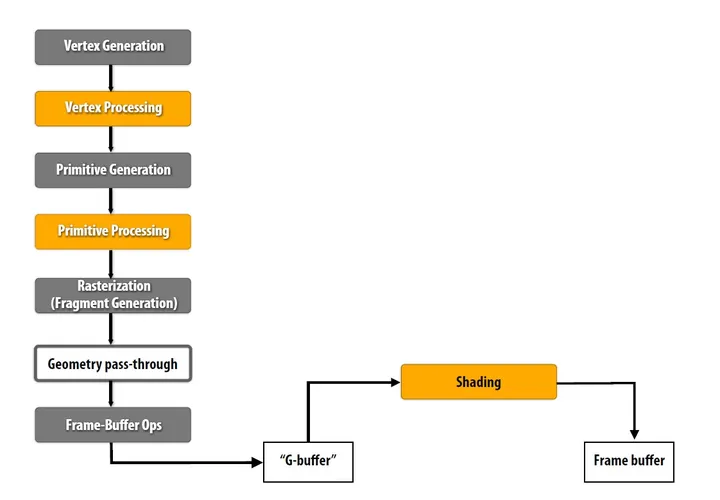 |
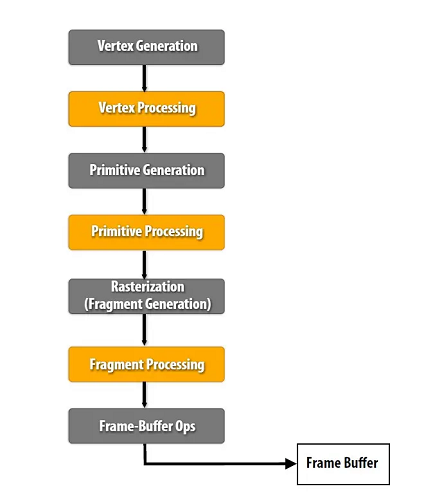 |
|---|

延迟渲染缺点产生的原因:
- 对MSAA支持不好:其实理论上MSAA是可以支持的,具体看这几篇文章延迟渲染为什么不支持MSAA?,延迟渲染与MSAA的那些事
- 无法渲染透明物体:因为在渲染透明物体时,要对透明物体排序,从后往前渲染透明物体,并且关闭了ZWrite,在延迟渲染的几何处理阶段,实际上就无法记录到透明物体的深度信息,透明物体就被当作不存在了;
- 占用显存带宽:因为延迟渲染需要使用G-buffer,往往还是多个G-buffer,存储这些G-buffer需要占用显存;
- 只能使用一种光照模型,因为延迟渲染计算光照的时候已经不知道每个像素是哪一个mesh的了;
延迟渲染的改进
延迟光照(LightPre-Pass/Deferred Lighting)
将G-Buffer的数据结构减小,从而减少带宽占用。
分块延迟渲染(Tile-BasedDeferred Rendering TBDR)(?有点胡言乱语,之后补充)
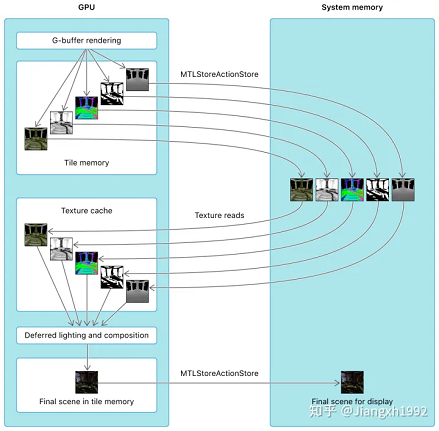
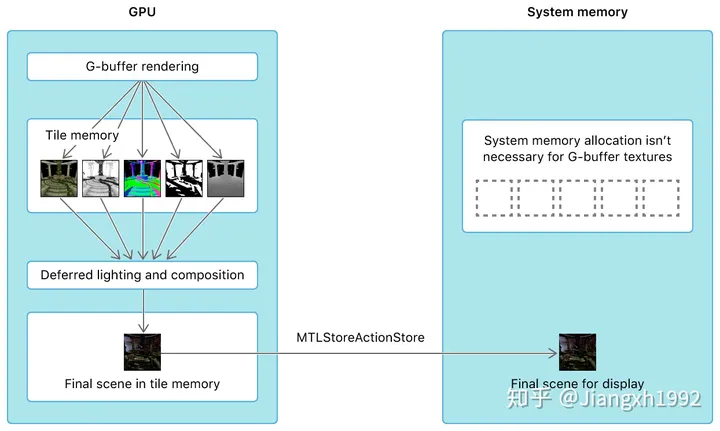
延迟渲染的瓶颈在于读写 G-buffer,在大量光源下,具体瓶颈将位于每个光源对 G-buffer的读取及与颜色缓冲区(color buffer)混合。但是不是每个片元都受到了全部光源的影响,对每个片元都遍历一次全部光源会产生浪费。于是,就想到把屏幕空间分块,事先计算并记录每个块中收到了那些光源的影响,之后渲染这个块的时候就只需要遍历这些光源即可。
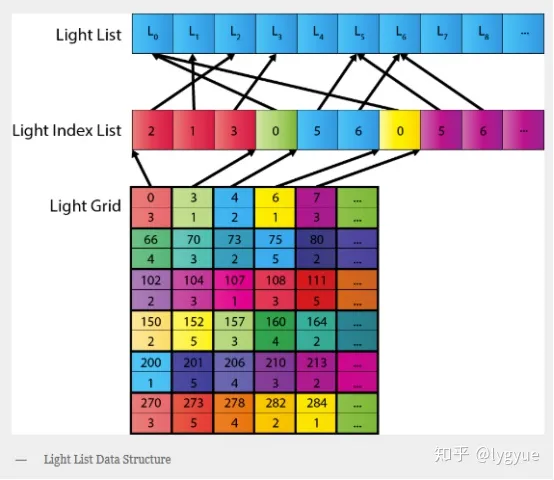
对于支持TBDR架构的GPU来说,分块还有一个好处是显著降低带宽。传统的延迟渲染由于G-buffer包含整个屏幕空间的像素,需要将G-buffer写入到系统内存中,之后第二个pass中的片元着色器再从系统内存中读取G-buffer进行计算,而分块之后,由于每个块的G-buffer包含的像素不多,可以直接将G-buffer存储在tile memory中,不需要再用第二个pass,可以直接计算。
 |
 |
|---|