侯捷C++-面向对象高级编程——类相关
access level(访问级别)
一般数据都要设置为private,需要外界调用的函数设置为public。在单例模式中,会将构造函数设置为private,确保只能有一个对象。
friend关键字可以设置友元,友元可以自由取得private成员。相同的类(class)的各种对象(objects)互为友元。
1 | |
构造函数
初始化列表
总是使用构造函数初始化列表!,不使用函数初始化列表会导致一些变量(比如下面的m_A)被初始化多次,造成性能浪费。因为不使用初始化列表时,是给m_A赋值,也就是先调用默认构造函数初始化了一个m_A对象,之后再给他赋值。
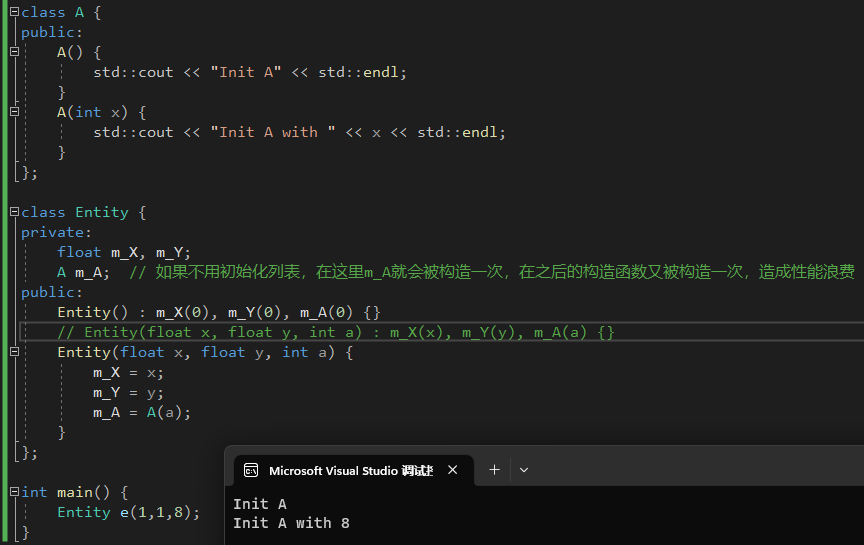 |
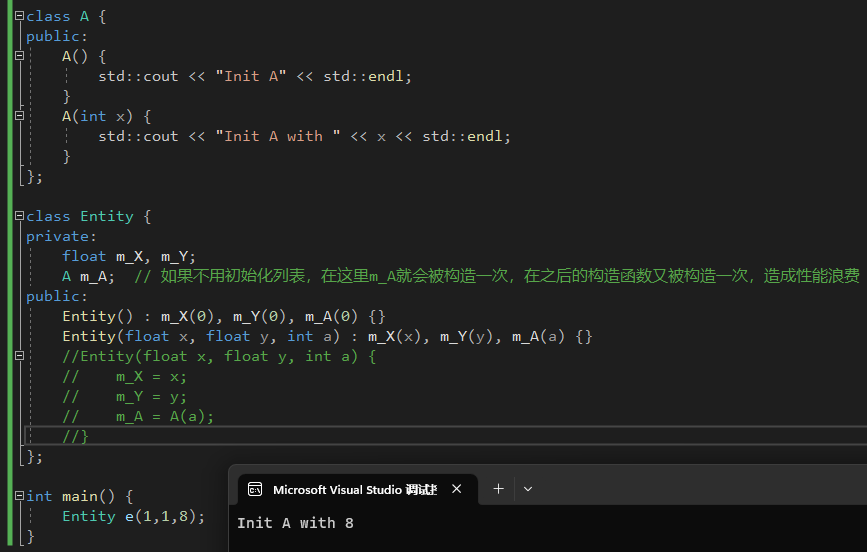 |
|---|
其次,使用初始化列表可以防止增添变量时修改函数体内部。并且,构造函数不只会给成员变量赋值,还有可能做其他操作,使用初始化列表可以将这两种逻辑分开,增加代码可读性。
总结:
- 提高效率,避免不必要的复制操作
- 便于维护,增添变量时不用修改函数体内部
- 增加可读性,将初始化变量和其他构造函数逻辑分开
拷贝构造函数
当类内有指针类型的成员变量时,需要手动写拷贝构造函数,进行深拷贝。
this指针
成员函数都有this指针。谁调用构造函数,谁就是this
1 | |
引用与指针
- 指针是一个地址,有自己的内存空间,引用是别名(底层也是一个指针,可以说是指针的一种特例)
- 指针可以指向其他对象,引用初始化之后就不能改变了
- 指针可以初始化为nullptr,引用必须被初始化为一个已有对象的引用
参数传递(passByValue vs passByRef)
1 | |
传值(byValue)顾名思义是只关注值,也就是说需要新建一个变量来存这个值,这造成了不必要的性能开销,而且对于值很复杂的变量(如一个很大的结构体),传递起来速度也会变慢。因此尽量传递引用,引用在底层就是一个指针,传递指针即避免了赋值的开销又保证了传递的数据量较小(一个指针的大小)。
既然引用是一个指针,那么就要考虑函数内的修改会改变内存中的值,从而影响其他使用这个变量的地方,所以经常用const来修饰引用,保证函数内不会对参数进行修改。对于不希望改变的函数参数,尽量总是使用 “const引用” 作为函数参数!
返回值传递(returnByValue vs returnByRef)
与参数传递类似,返回值返回引用可以避免赋值开销,但是当返回值为临时变量(临时变量会随函数而消失,造成内存泄漏)时不能返回引用。
传递者无需知道接收者是以reference形式接收。 这句话主要是指出引用的优势,使用引用不需要确保使用者事先知道你是否用了引用。
1 | |
操作符重载
操作符就是一种函数,C++提供操作符来提高代码可读性。
1 | |
在重载操作符时需要考虑连加的情况,也就是要注意重载+=函数的返回值。
拷贝赋值重载
当类内有指针类型的成员变量时,要编写拷贝赋值函数(重载operator=)
1 | |
注意点:
- 检测自我赋值!
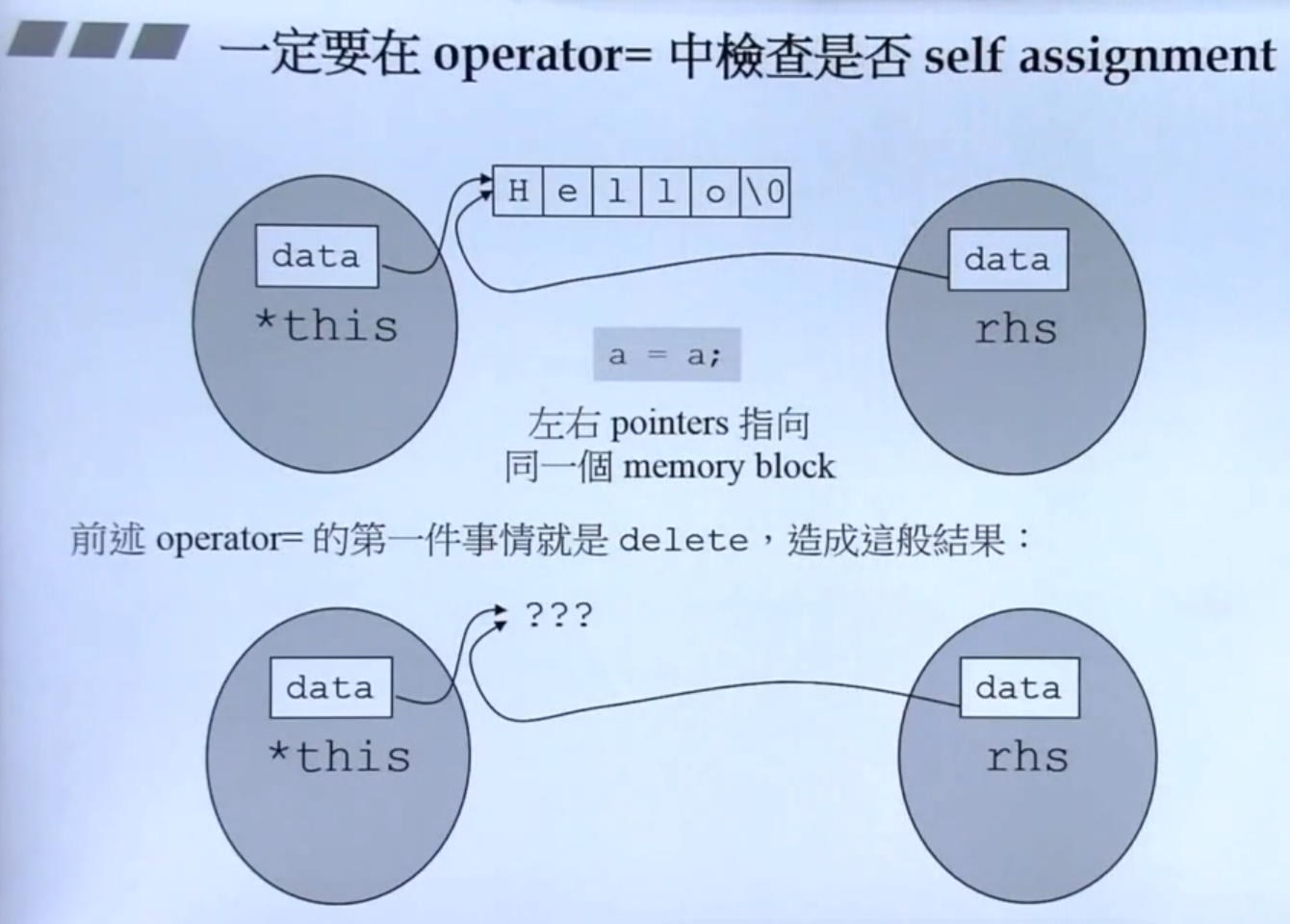
- 先删除原本的空间! 防止产生内存泄漏;
- 分配新空间,进行深拷贝!
output函数(<<)
output函数一定要在类外定义,不要定义为成员函数!
1 | |
内存管理
堆(heap),栈(stack)
栈是存在于某作用域(Scope)的一块内存空间(memory space)。如当调用某个函数,函数本身即会形成一个栈来放置接受的参数,返回的地址以及函数内的临时变量。
堆或称为system heap,是指由操作系统提供的一块全局内存空间,程序可以动态分配从中获得若干区块。
生命周期
- 栈中的对象,其生命在作用域(scope)结束之后结束,也就是其内存会被自动回收。
- static修饰的静态对象,其生命随程序结束而结束,static修饰的对象并不是真正意义上的全局对象,其在link阶段是局部的,他们只对同一个 编译单元(.obj) 可见。
- 全局对象,其生命随程序结束而结束。
- 堆中的对象,其生命周期完全由程序员决定,要警惕内存泄漏。
1
2
3
4
5class Complex {...}
...
{
Comlpex* p = new Complex;
} // 内存泄漏,指针p的生命结束,但是p所指的堆上的对象仍然存在,这片内存就再也不能用了,相当于丢了这部分内存,这就叫内存泄漏。
new与delete
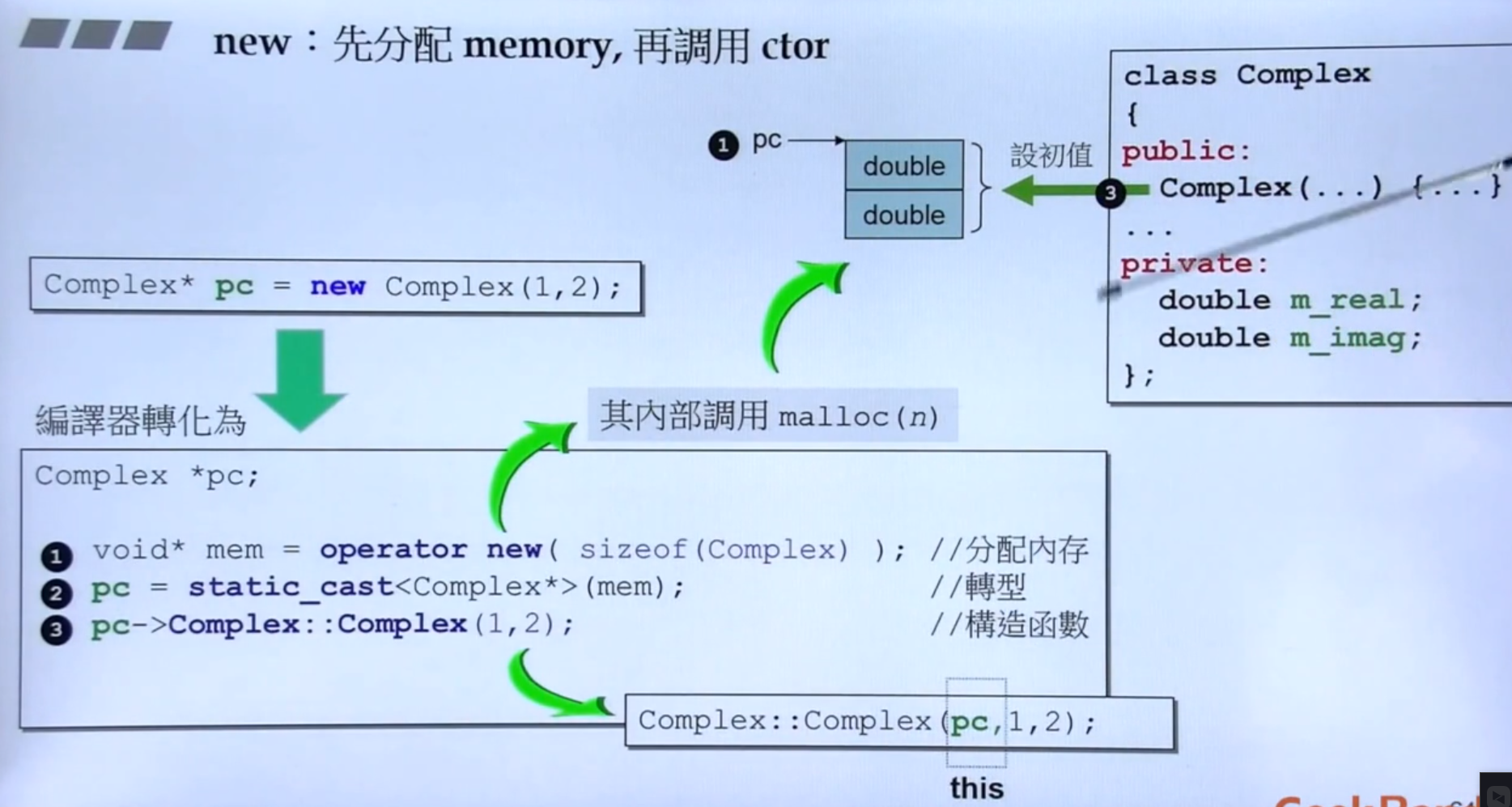
可以看出 new 先调用用 malloc 分配内存,再调用构造函数(可以看出这里把pc当作了this指针,印证了谁调用构造函数谁就是this指针 )。
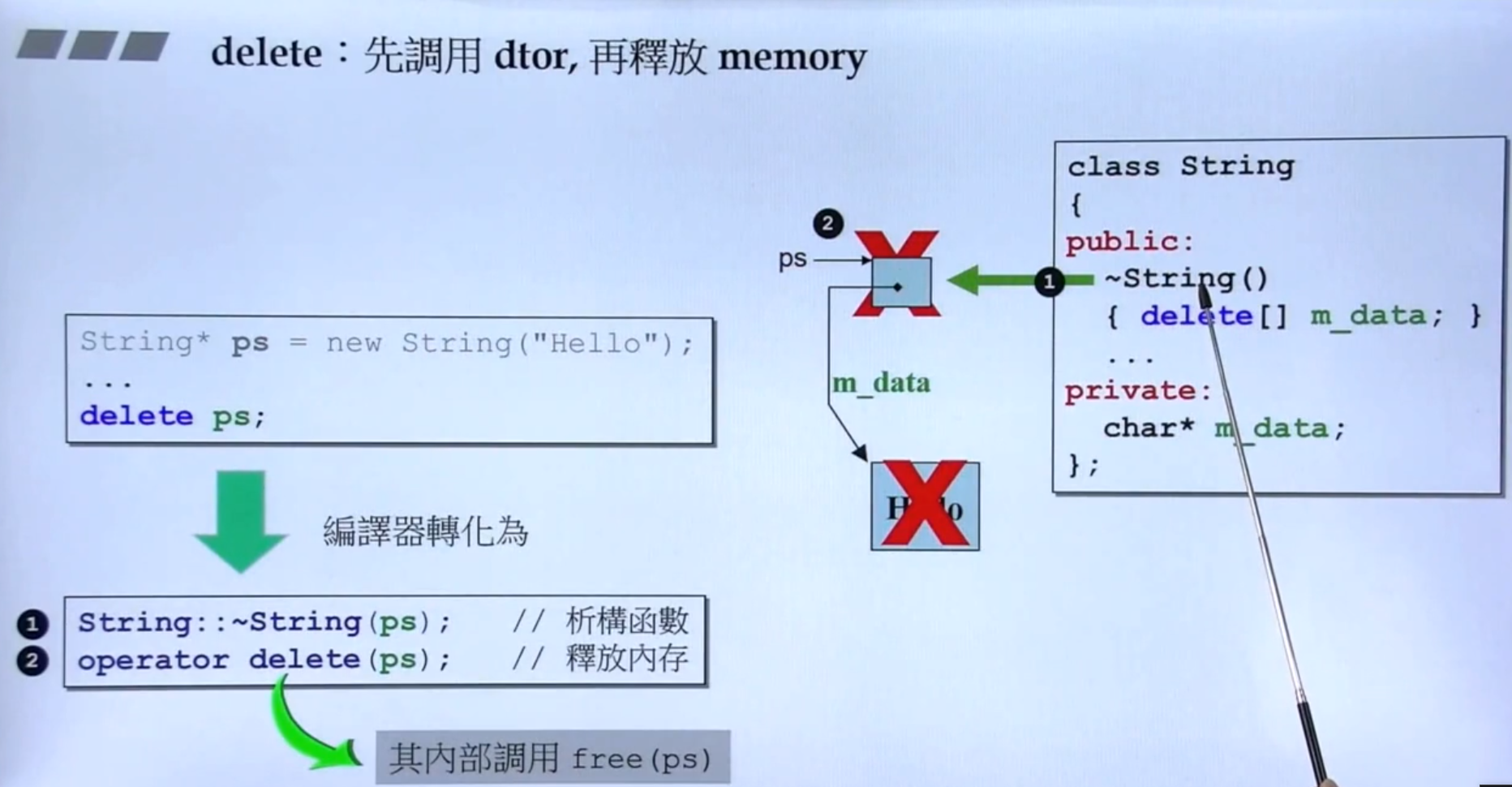
可以看出 delete 先调用析构函数,再调用 free 释放内存。如上图案例,其中先调用析构函数释放动态分配的内存,再释放指针本身的内存。
动态分配的内存细节(VC编译器)

在调试模式下,编译器会为了方便调试多加一些灰色的内存,同时不管是不是调试模式,编译器都会在内存首尾添加cookie(用来记录分配出去的内存块大小),并且,分配内存必须是16的整数倍,所以填补一些pad内存使这块内存变为16的整数倍。

在动态分配数组时,大致与上面相同,但是需要多4个字节存储数组的大小。
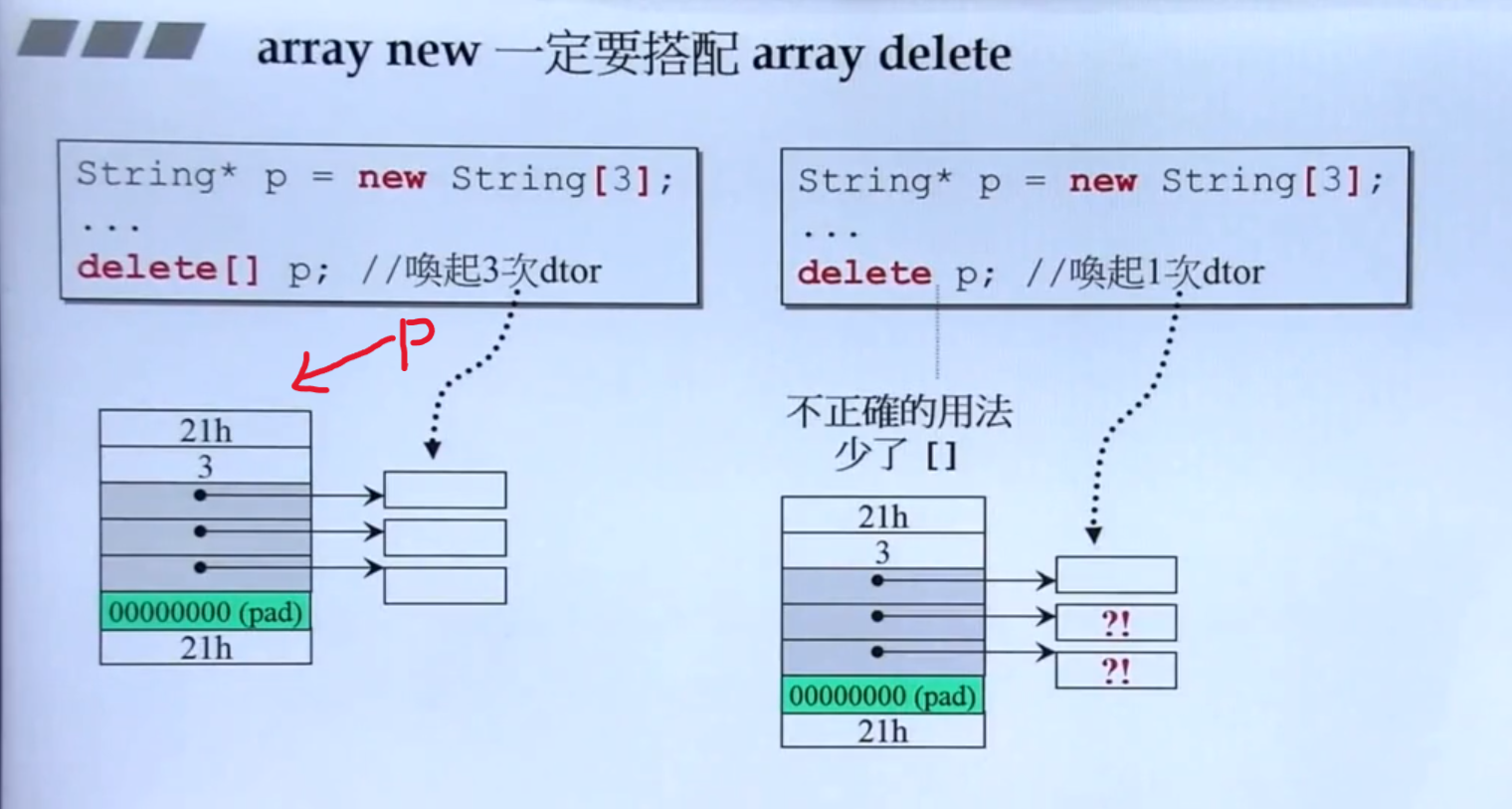
array new 一定要搭配 array delete! 否则,指针数组中的指针指向的区域会发生内存泄漏。如果不用delete[] p 而使用 delete p,会把这块内存完美删掉,不会产生任何内存泄漏,但是由于编译器不知道删除的是一个数组,就只会调用一次析构函数,数组中其他指针指向的内存就没有被析构函数释放,造成内存泄漏。
总结C++的内存布局
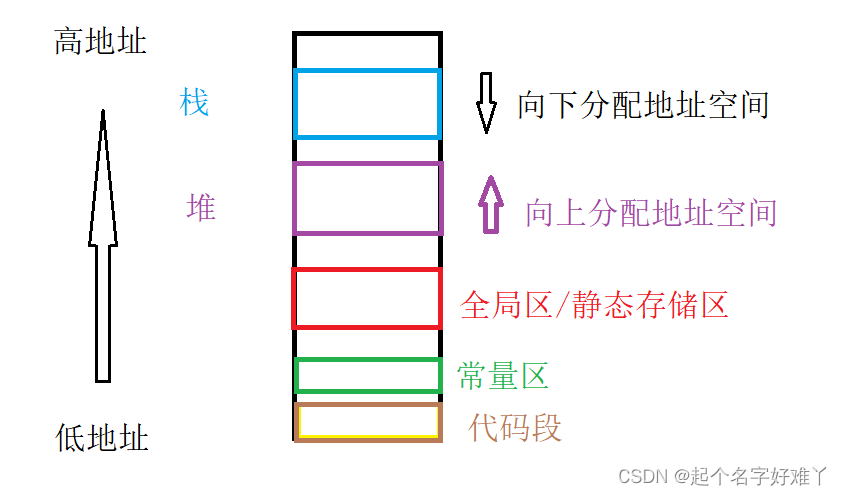
- 栈:系统分配的内存区域,大小较小一般为1M;存放局部变量,返回值,参数;由操作系统自动管理内存的申请和释放,栈由于由操作系统管理因此分配效率高,栈内地址由高向下;
- 堆:专门开辟出的一片空间用于给程序员动态申请内存使用,大小较大一般为几个G;存放malloc,new出来的变量;需要程序员手动管理内存的申请和释放,因此 分配效率不如栈,堆内地址 自下而上;
- 全局/静态存储区:存放 全局变量和静态变量,程序结束自动释放;初始化了的全局和静态变量放一起,没初始化的放一起,两个区域相邻;
- 常量存储区:存放常量如 string s=”hello world” 中的 “hello world”;
- 代码存储区:存放代码,函数体,不可更改;生命周期与程序相同;
内存对齐
内存对齐的原因
关键在于CPU存取的效率问题。计算机从内存中取数据是按照固定长度的,如在32位机上,CPU每次都取32bit数据,也就是4字节,如果不进行对齐,要取出两块地址中的数据,要进行掩码和移位操作,写入目标寄存器内存,效率很低,因此要内存对齐;
对齐原则
- 结构体变量的首地址能被其最宽基本类型成员的对齐值整除
- 结构体内每个成员相对于起始地址的偏移量能够被该变量的大小整除
- 结构体总体大小能被最宽成员大小整除
如不满足以上条件,编译器会进行填充(padding)
如何对齐
字节对齐的数据依次声明,最后将小成员组合在一起,不要把小成员掺杂在对齐的数据之间;
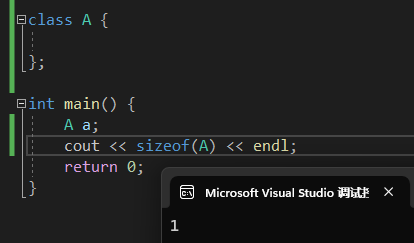
类的大小
- C++中一个空类的大小是1
- 继承一个空类时,基类的大小就是0了,而不是1+1=2:
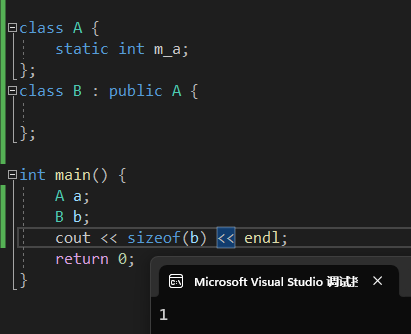
- 有虚函数的类,会有一个虚函数指针
- static成员变量不存储在对象中,存储在 全局/常量存储区:
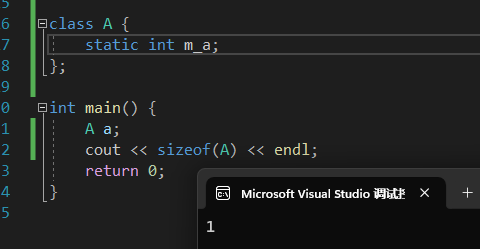
- static函数存储在代码区,而不是全局/常量存储区