侯捷C++-STL
STL全称 Standard Template Library(标准模板库),C++ Standard Library标准库中有百分之八十都是STL;
参考网站:
gcc.gnu.org
cplusplus
cppreference
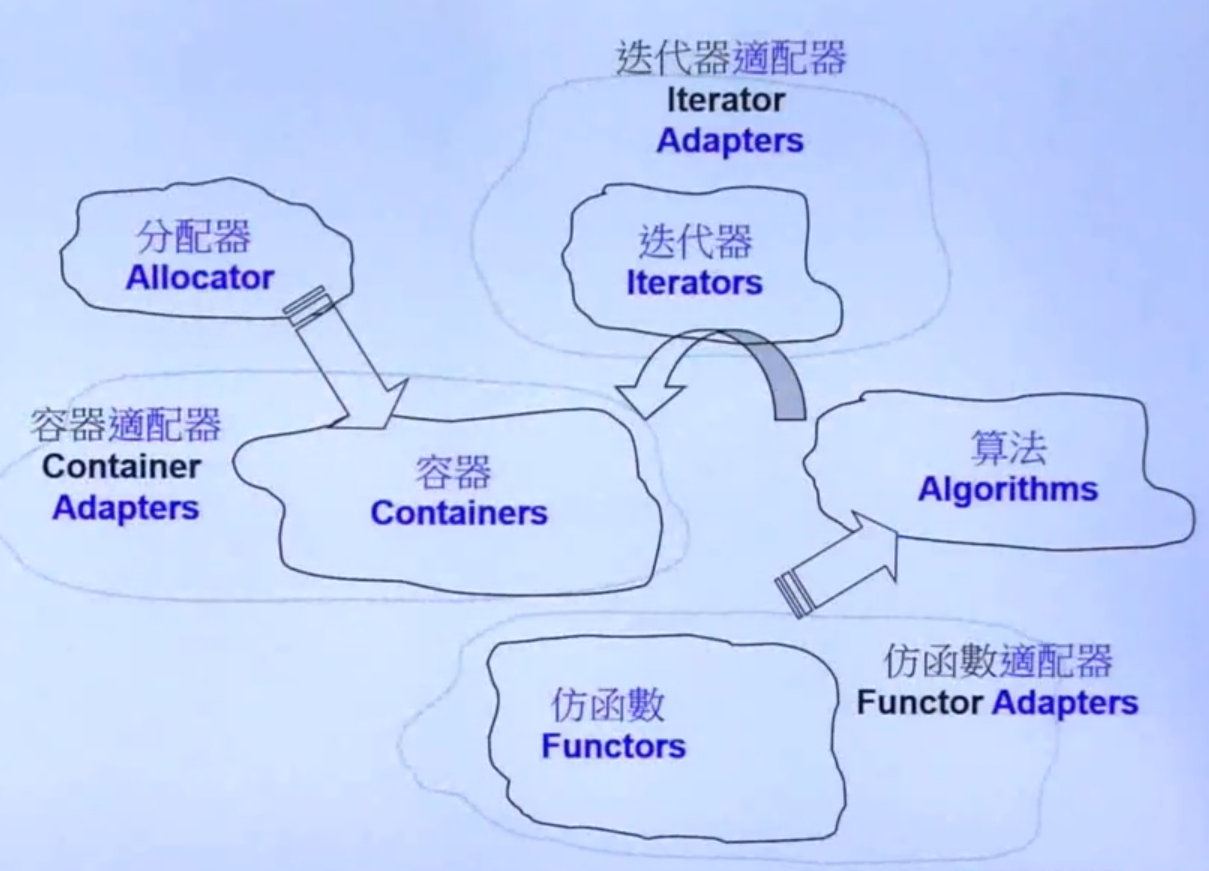
STL简介
 |
 |
|---|
1. 容器(Containers)
2. 分配器(Allocators)
3. 算法(Algorithms)
4. 迭代器(Iterators)
5. 适配器(Adapters)
6. 仿函数(Functors)
STL设计的思想不是OOP(Object-Oriented Progragmming)而是GP(Generic Programming)泛化编程,这种思想将数据和方法分开,在STL里的明显应用就是把数据放在容器中,让算法通过迭代器实现对数据的操作。这种方法可以方便设计容器的团队和设计算法的团队可以独立开发,只要双方迭代器互通即可。
STL基础——操作符重载和模板
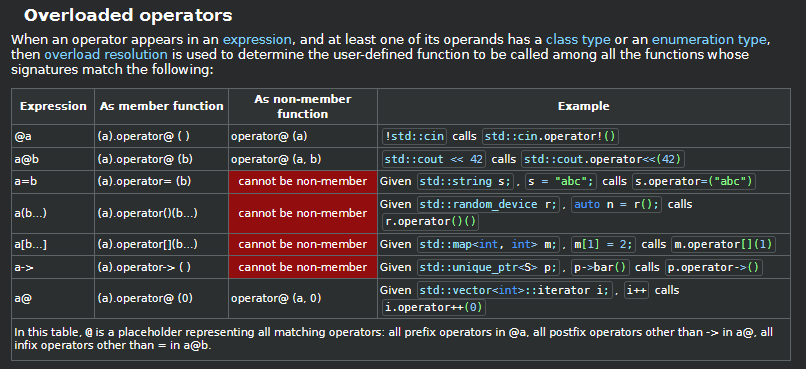
操作符重载
模板
类模板
1 | |
函数模板
1 | |
特化
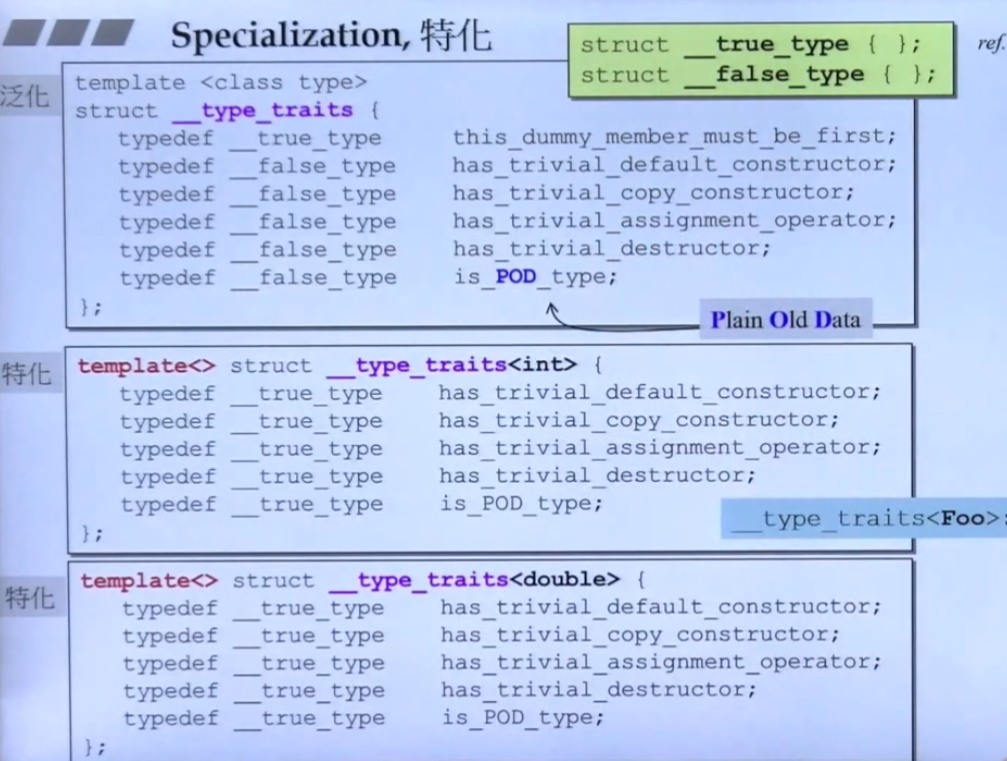
最基础的模板函数可以理解为是一种 泛化,不管参数是什么类型都一样操作,C++也提供了 特化 来进一步提高效率,特化就是当参数是某种类型时,专为这种类型设计对应的函数。
偏特化

偏特化(Partial Specialization) 如上图所示,当一部分参数是某种类型时,为其设计对应的函数,可以理解为 个数 上的偏特化;
另外,还有一种偏特化是 范围 上的偏特化,如上图所示。
分配器 allocators
每个容器都有一个分配器作为参数,分配器负责真正去申请开辟内存;一般我们不需要直接用allocator,让容器去用即可。

可以看出在VC6中,allocator就是调用了 operator new 和 operator delete 去申请和释放内存。而我们又知道,operator new 和 operator delete 底层分别由 malloc 和 free 实现,malloc真正分配的内存会多出一些(cookie确定内存大小,debug相关内存,变量内存,padding内存)
malloc 在分配内存的时候不可避免的要多分配一些内存,尤其是cookie是不能省略的(debug在release模式下就没了,padding也有可能恰好没有),因为在拿一块内存的时候系统需要知道拿了多大才能在回收的时候正确回收,cookie 就是为了记录申请的内存大小的;
那么就有一个问题,如果我们真正想申请的内存很小,比如就1个字节,但是为了申请这一点内存,需要额外的申请cookie的8个字节,这岂不是很浪费!那么为了避免这个问题,一些编译器(G2.9)的allocator会做一些特殊的操作避免这种浪费,下面会介绍一种操作:**__pool_alloc**;
__pool_alloc
想要不分配cookie,那先要想cookie的作用,上面已经说了很多次了,cookie就是为了记录申请的内存的大小,当我们没有用容器的时候,cookie就没办法省掉,因为我们申请的内存确实是有大有小的,但是当我们使用容器时,容器内部每个变量的内存一定是一样的! 那么我们就可以不记录容器中每个变量所占的内存大小了,这就是 __pool_alloc 实现的基础。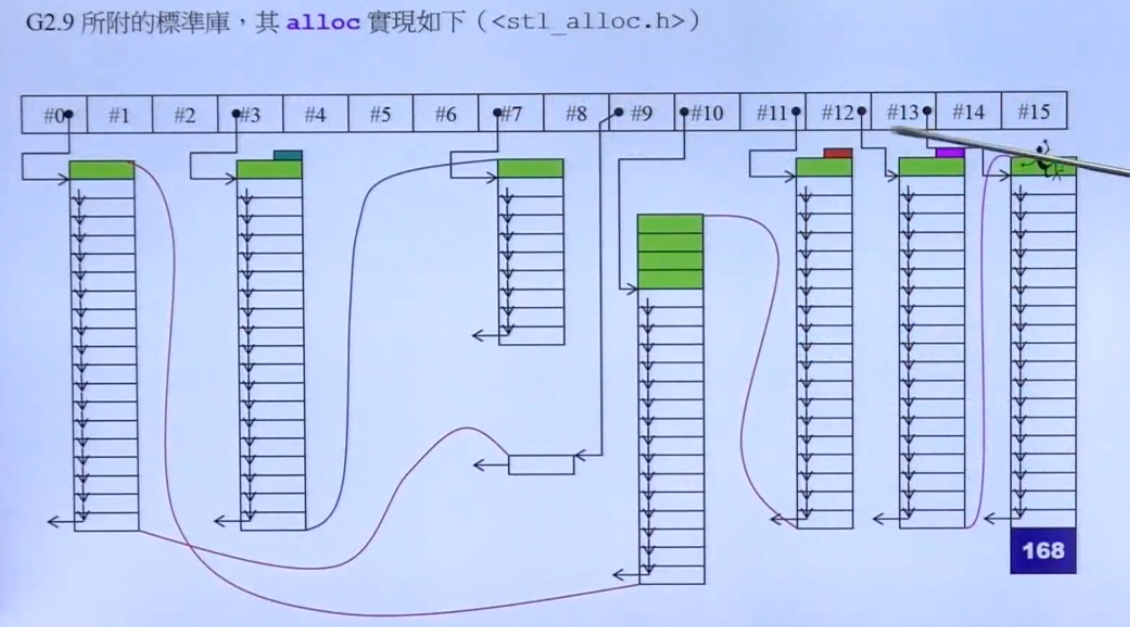
__pool_alloc 设计了如图所示的16个链表,**#0指向的链表每块内存大小为8字节,#1指向的链表每块内存大小为16字节,#2指向的链表每块内存大小为24字节,以此类推。在使用时,根据容器中元素的内存大小,分配能满足其的最小的内存块,比如容器中元素内存为20,那就选择 #2 指向的链表,并将元素内存填充到24,一次性向系统申请一大片内存(只用额外分配两个cookie),其中每块都是24,将容器中的元素依次放进每个块中,当链表中的内存不够时,再去申请一大片内存。这样就能节省大量的内存空间,因为只用在每次申请大片内存时额外分配cookie。
同时,_pool_alloc不仅在内存占用上有优势,在效率上也有优势,每次调用malloc申请内存时,需要从用户态转到内核态,这会浪费很多时间,因此_pool_alloc减少内存分配次数也可以减少操作系统的状态切换。**
这么好的allocator算法,在G4.9又不是默认的了,也不知道为什么,但是该名为 __pool_alloc 可以手动指定使用。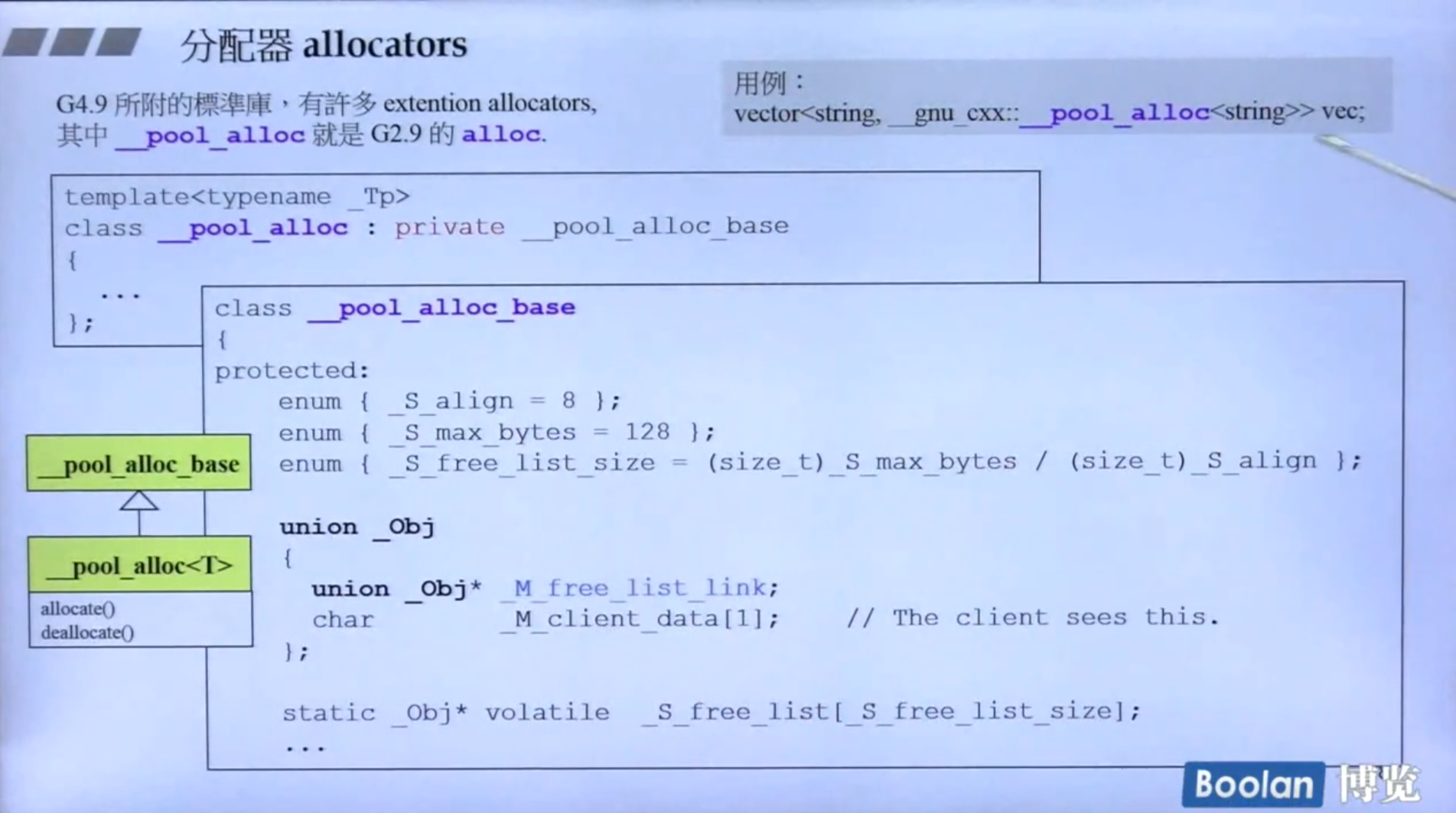
容器
内容较多,见另一篇笔记;
迭代器
迭代器是算法与容器间的桥梁;STL使用泛型编程把方法与数据分开,那么就需要一个东西把二者联系起来,迭代器充当这个角色,迭代器在使用上和指针类似,有些迭代器(vector)就是一个指针;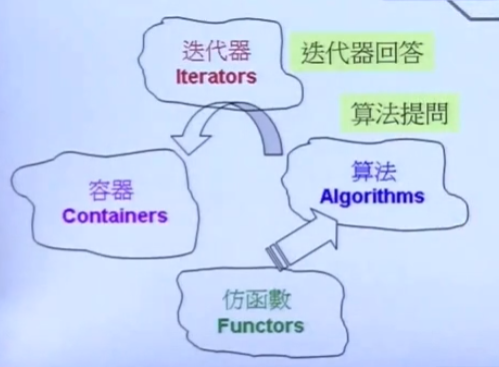
迭代器要能从容器中取出元素交给算法去操作,迭代器也要能 “回答算法的提问”,算法可能会根据容器内元素类型的不同进行不同的操作,所以迭代器还要能告知算法一些元素的特性;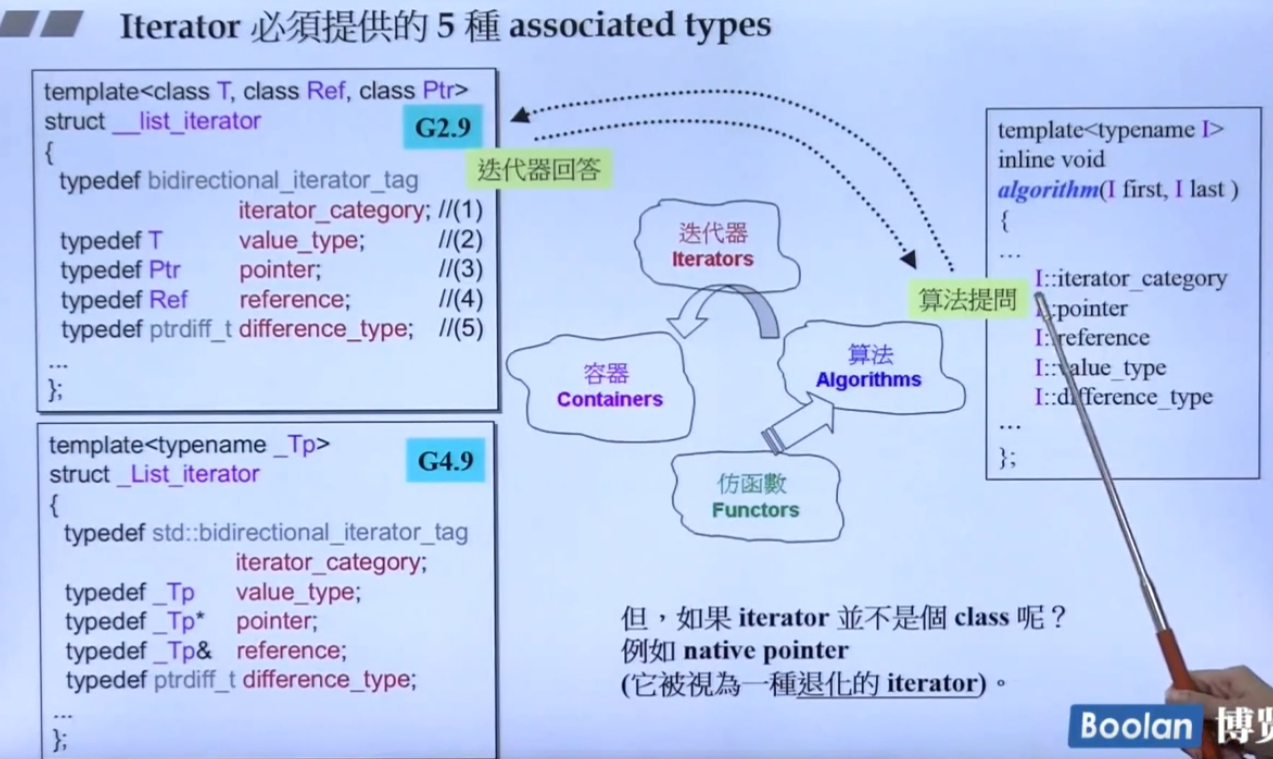
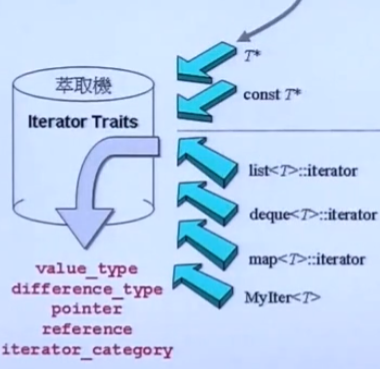
一种实现思路如图,规定迭代器要指明五种特性都是什么(用typedef实现),迭代器里用typedef指明了这些属性之后,算法直接取得即可。
但是有一种情况会出问题,算法不是专为容器设计的,也就是说非迭代器也应该能用(况且迭代器本身的设计理念就是当作一个指针),普通的指针比如(int*)也应该能使用算法,因此STL设计了 iterator_traits;
iterator_traits
traits的中文是属性、特性,在这里可以把他理解成一个萃取器,我们要求通过这个 萃取器 得到我们想要的属性;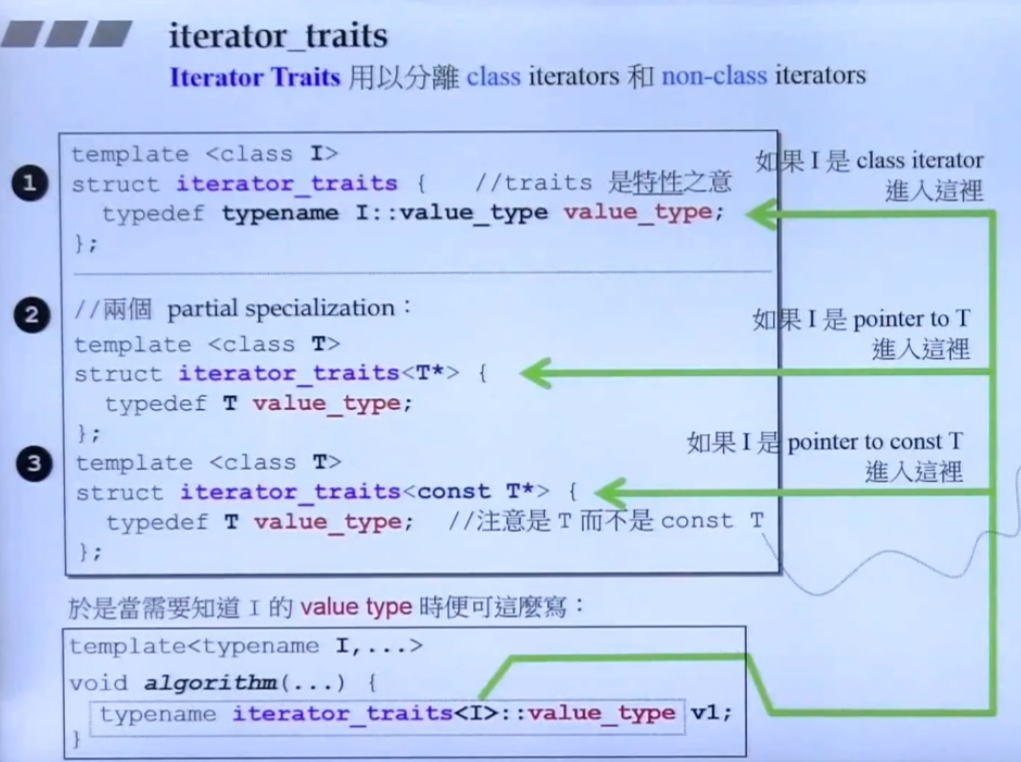
 s
s
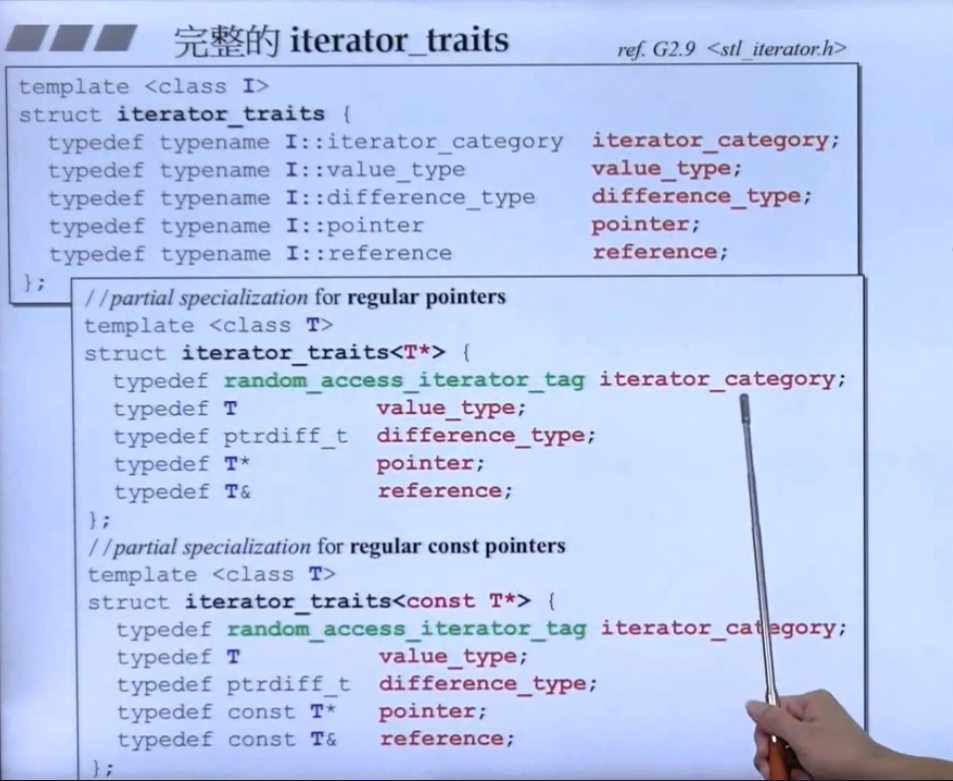
iterator_traits的实现使用了 范围偏特化,有一个基础的泛化操作,就是从类(迭代器类)中取特性,之后定义了两个偏特化模板,当T是指针时以及T是常量指针时,直接返回指针的类型;
完整的iterator_traits如下,STL规定迭代器要 “回答” 算法的五个问题:
- 容器中元素类型 value_type
- 容器中元素指针类型 pointer
- 容器中元素引用类型 reference
- 迭代器类型 iterator_category
- 两个迭代器之间的最大距离 difference_type
iterator_category
在上面介绍iterator_traits时我们看到iterator_traits要回答当前迭代器类型iterator_category,迭代器类型有以下五种: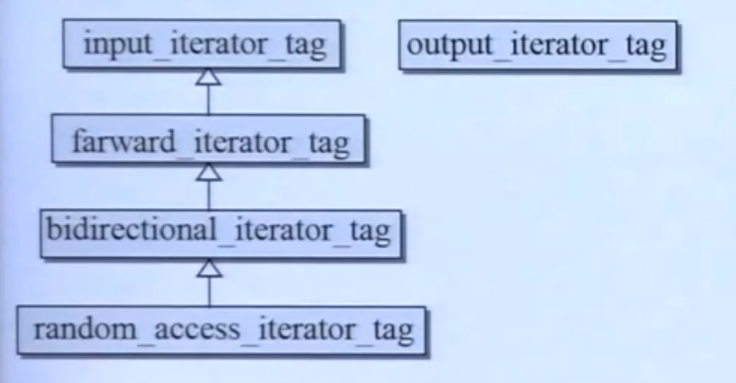
针对不同的容器其迭代器类型也不同,反应该容器的迭代器访问性质:
- 数组Array:random_access_iterator_tag 随机访问
- Vector:random_access_iterator_tag
- Deque:random_access_iterator_tag
- List:bidirectional_iterator_tag 双向前进(不能随机访问)
- Forward-List:forward_iterator_tag 单向前进
- Set/MultiSet:bidirectional_iterator_tag
- Map/MultiMap:bidirectional_iterator_tag
- Unordered Set/MultiSet:forward_iterator_tag
- Unordered Map/MultiMap:forward_iterator_tag
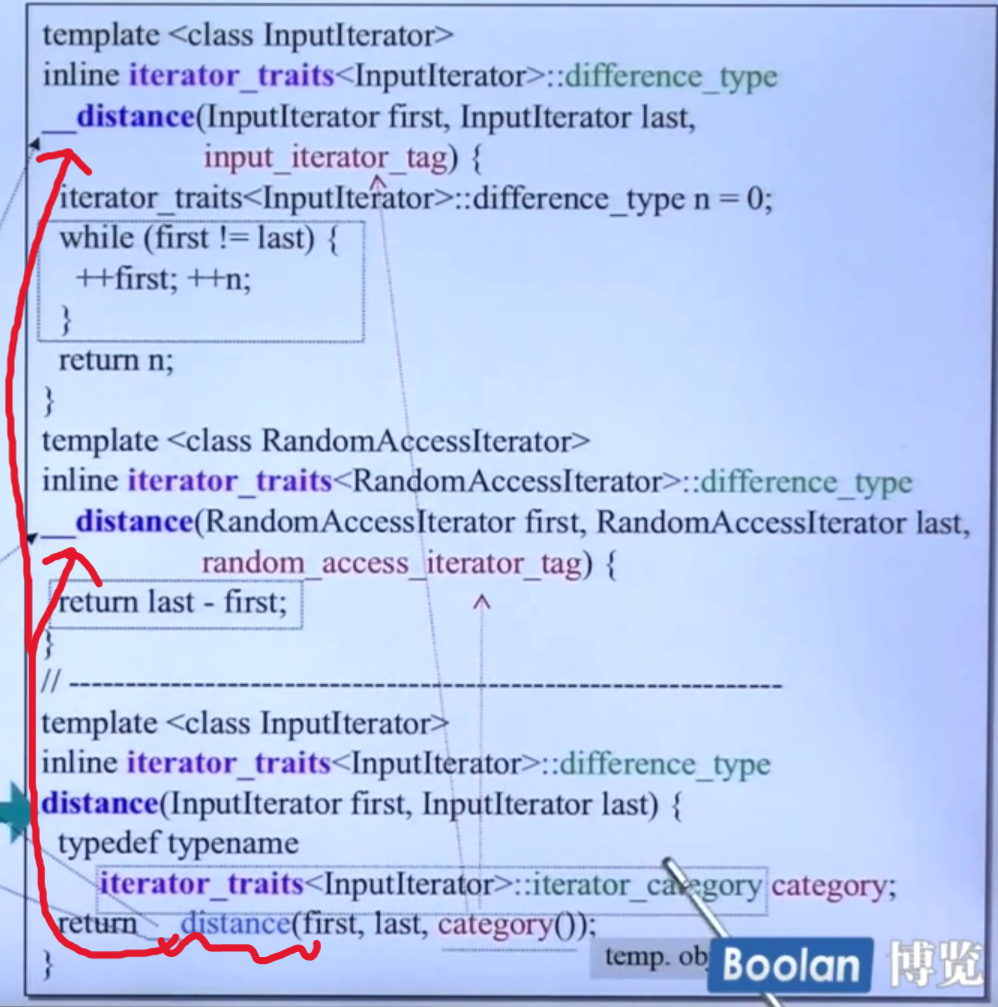
iterator_tag有什么用呢,如有算法希望知道两个迭代器之间的距离,这就需要知道迭代器的类型,如果迭代器类型是random_access_iterator_tag 支持随机访问,也就是连续存储,就可以直接相减,若不是则就只能步进并计数。同理,如有算法希望前进迭代器也需要根据不同的迭代器类型选择适合的前进策略:
 |
 |
|---|
思考:为什么迭代器类型本身不使用枚举来实现,反而用类通过继承来实现?
其实看上面两个算法的代码我们就可以看出,使用类实现不需要为每个类型都写一个函数实现,而可以使用基类参数;
算法

算法是一个函数模板;算法是用来操作数据的,但是算法对存放数据的容器的实现一无所知(也完全不需要了解),只能通过iterator迭代器得到想要的数据,上面在迭代器章节我们了解到,迭代器通过iterator_traits为算法提供信息,如iterator_category,difference_type等信息,来方便算法根据不同的数据类型选择不同的算法,以提高效率。
算法的形态大致如下,都是模板函数,并且都有两个迭代器参数:
1 | |
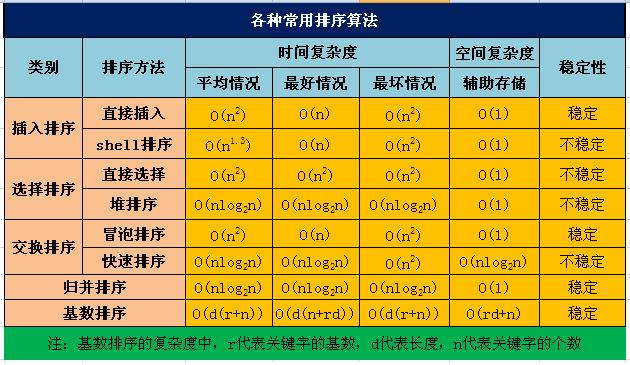
STL的排序算法
快速排序、插入排序和堆排序;当数据量很大的时候用快排,划分区段比较小的时候用插入排序,当划分有导致最坏情况的倾向的时候使用堆排序。
各种排序算法的原理和时间复杂度
判断一个排序算法是否稳定就是看 相同的数位置会不会变化;
快排代码:
1 | |
最坏情况就是没有划分,时间复杂度为O(n^2);